
Apache InLong (incubating) has been renamed from the original Apache TubeMQ (incubating) from 0.9.0. With the name change, InLong has also been upgraded from a single message queue to a one-stop integration framework for massive data. InLong supports data collection, aggregation, caching, and sorting, users can import data from the data source to the real-time computing engine or land to offline storage with a simple configuration.
The just-released version 0.11.0-incubating is the third version after the name changed. This version includes next features:
- Lower the user's threshold for use further. Support all modules of InLong to be deployed on Kubernetes, and refactor the official website, so that users can more easily access related documents.
- Support more usage scenarios, increase the data flow direction of
Dataproxy -> Pulsar, and cover scenarios with higher requirements for data integrity and consistency. - Supports SDKs in more languages for TubeMQ. This version opens the production-level TubeMQ Go SDK, which is convenient for users who use the Go language to access
This version closed more than 80 issues, including four significant features and 35 improvements.
Apache InLong(incubating) Introduction
Apache InLong is a one-stop integration framework for massive data donated by Tencent to the Apache community. It provides automatic, safe, reliable, and high-performance data transmission capabilities to facilitate the construction of streaming-based data analysis, modeling, and applications.
The Apache InLong project was originally called TubeMQ, focusing on high-performance, low-cost message queuing services. In order to further release the surrounding ecological capabilities of TubeMQ, we upgraded the project to InLong, focusing on creating a one-stop integration framework for massive data.
Apache InLong uses TDBank internally used by Tencent as the prototype, and relies on trillion-level data access and processing capabilities to integrate the entire process of data collection, aggregation, storage, and sorting data processing. It is simple to use, flexible to expand, stable and reliable characteristic.
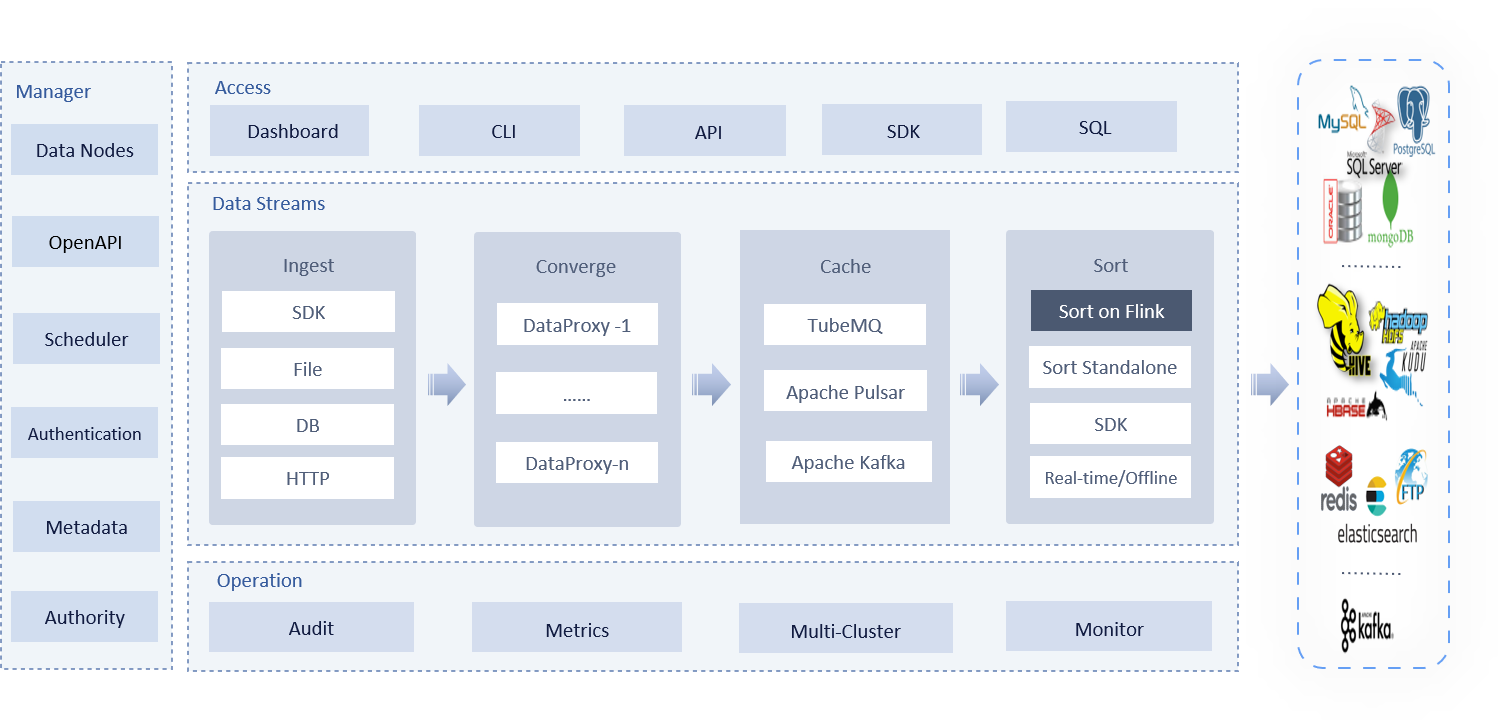
Apache InLong serves the entire life cycle from data collection to landing, and provides different processing modules according to different stages of data, including the next modules:
- inlong-agent, data collection agent, supports reading regular logs from specified directories or files and reporting data one by one. In the future, DB collection and HTTP reporting capabilities will also be expanded.
- inlong-dataproxy, a Proxy component based on Flume-ng, supports data transmission blocking, placing retransmission, and has the ability to forward received data to different MQ (message queues).
- inlong-tubemq, Tencent's self-developed message queuing service, focuses on high-performance storage and transmission of massive data in big data scenarios and has a relatively good core advantage in mass practice and low cost.
- inlong-sort, after consuming data from different MQ services, perform ETL processing, and then aggregate and write the data into Apache Hive, ClickHouse, Hbase, IceBerg, etc.
- inlong-manager, provides complete data service management and control capabilities, including metadata, OpenAPI, task flow, authority, etc.
- inlong-website, a front-end page for managing data access, simplifying the use of the entire InLong control platform.
What’s New in Apache InLong(incubating) 0.11.0
InLong on Kubernetes
Apache InLong includes multiple components such as data collection, data aggregation, data caching, data sorting, and cluster management and control. In order to facilitate users to use and support cloud-native features, all components currently support deployment in Kubernetes. Thanks to @shink for contributing to this feature. For specific details, please refer to INLONG-1308.
Open up dataproxy->pulsar data flow
Before version 0.11.0, InLong's data caching layer could only support TubeMQ. TubeMQ is very suitable for scenarios with huge data volumes, but in extreme scenarios, there may be a small amount of data loss. To provide data reliability, the Inlong added support for Apache Pulsar in version 0.11.0. Now InLong backend can support data flow agent -> dataProxy -> tubeMQ/pulsar -> sort. The introduction of Pulsar makes the application scenarios covered by InLong more abundant, which could meet the needs of more users.
Thanks to @baomingyu for his contribution to this feature. For more details, please refer to INLONG-1330.
Go SDK for InLong TubeMQ
Before version 0.11.0, InLong TubeMQ supports SDKs in three languages: Java, C++, and Python. With more and more applications of Go language, the demand for Go language SDK in the community is also increasing. Version 0.11.0 was officially introduced to the Go language SDK of TubeMQ. The multilingual SDK is enriched, and the difficulty of access and use for Go language users is also reduced. Thanks to @TszKitLo40 for contributing to this feature. For more details, please refer to:
refactor the official website
In version 0.11.0, InLong uses Docusaurus to refactor the official website to provide a more concise and intuitive document management and display. Thanks to @leezng for his contribution to this feature. For more details, please refer to:
In addition to the above major features, InLong 0.11.0 version has other key improvements, including but not limited to:
- Added contribution guidelines in the main Repo, INLONG-1623
- Add Inlong-Manager to DataProxy configuration management, INLONG-1595
- Optimized the GitHub issue template, INLONG-1585
- Code Checkstyle optimization, INLONG-1571, INLONG-1593, INLONG-1593, INLONG-1662
- Agent introduces message filter, INLONG-1641
The 0.11.0 version also fixes ~45 bugs. Thanks to all the contributions who have contributed to the Inlong community (in no particular order):
- shink
- baomingyu
- TszKitLo40
- leezng
- ruanwenjun
- leo65535
- luchunliang
- pierre94
- EMsnap
- dockerzhang
- gosonzhang
- healchow
- guangxuCheng
- yuanboliu
Apache InLong(incubating) follow-up planning
In the subsequent version planning of InLong, we will further release the capabilities of InLong to cover more usage scenarios, mainly including
- Support Apache Pulsar full link data access capabilities, including back-end processing and front-end management capabilities.
- Support data flow such as ClickHouse, Apache Iceberg, Apache HBase, etc.