
InLong: the sacred animal in Chinese myths stories, draws rivers into the sea, as a metaphor for the InLong system to provide data access capabilities.
Apache InLong is a one-stop integration framework for massive data that provides automatic, secure and reliable data transmission capabilities. InLong supports both batch and stream data processing at the same time, which offers great power to build data analysis, modeling and other real-time applications based on streaming data. The 0.12.0-incubating just released mainly includes the following:
- Provide automatic, safe, reliable and high-performance data transmission capabilities, while supporting batch and streaming
- Refactor the document structure of the official website to facilitate users to consult related documents based on the main line
- The whole process supports Pulsar data flow, and completes the whole process coverage of high-performance and high-reliability scenarios
- Full-process support indicators, including JMX and Prometheus output
- The first phase of data audit and reconciliation, write audit data to MySQL
This version closed about 120+ issues, including four major features and 35 improvements.
Apache InLong(incubating) Introduction
Apache InLong is a one-stop integration framework for massive data donated by Tencent to the Apache community. It provides automatic, safe, reliable, and high-performance data transmission capabilities to facilitate the construction of streaming-based data analysis, modeling, and applications.
The Apache InLong project was originally called TubeMQ, focusing on high-performance, low-cost message queuing services. In order to further release the surrounding ecological capabilities of TubeMQ, we upgraded the project to InLong, focusing on creating a one-stop integration framework for massive data.
Apache InLong uses TDBank internally used by Tencent as the prototype, and relies on trillion-level data access and processing capabilities to integrate the entire process of data collection, aggregation, storage, and sorting data processing. It is simple to use, flexible to expand, stable and reliable characteristic.
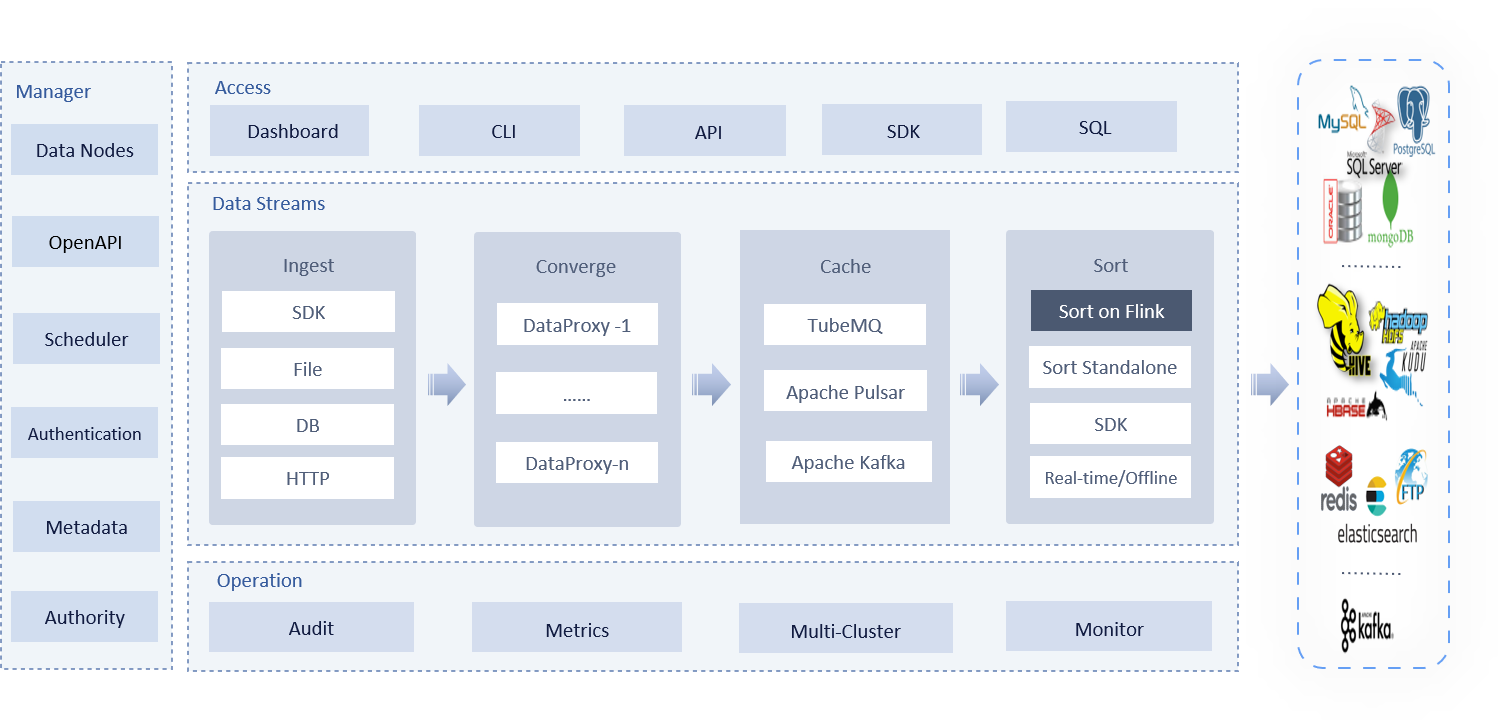
Apache InLong serves the entire life cycle from data collection to landing, and provides different processing modules according to different stages of data, including the next modules:
- inlong-agent, data collection agent, supports reading regular logs from specified directories or files and reporting data one by one. In the future, DB collection and HTTP reporting capabilities will also be expanded.
- inlong-dataproxy, a Proxy component based on Flume-ng, supports data transmission blocking, placing retransmission, and has the ability to forward received data to different MQ (message queues).
- inlong-tubemq, Tencent's self-developed message queuing service, focuses on high-performance storage and transmission of massive data in big data scenarios and has a relatively good core advantage in mass practice and low cost.
- inlong-sort, after consuming data from different MQ services, perform ETL processing, and then aggregate and write the data into Apache Hive, ClickHouse, Hbase, IceBerg, etc.
- inlong-manager, provides complete data service management and control capabilities, including metadata, OpenAPI, task flow, authority, etc.
- inlong-website, a front-end page for managing data access, simplifying the use of the entire InLong control platform.
What’s New in Apache InLong(incubating) 0.12.0
1. Support Apache Pulsar data cache
In version 0.12.0, we have completed the data reporting capability of FileAgent→DataProxy→Pulsar→Sort. So far, InLong supports high-performance and high-reliability data access scenarios: Compared with the high-throughput TubeMQ, Apache Pulsar can provide better data consistency and is more suitable for scenarios that require extremely high data reliability. For example, finance and billing.

Thanks to @healchow, @baomingyu, @leezng, @bruceneenhl, @ifndef-SleePy and others for their contributions to this feature. For more information, please refer to INLONG-1310incubator-inlong/issues/1310), please refer to [Pulsar usage example](https://inlong.apache. org/zh -CN/docs/next/quick_start/pulsar_example/) to get the usage guide.
2. Support JMX and Prometheus metrics
In addition to the existing file output metrics, the various components of InLong began to gradually support the output of JMX and Prometheus metrics to improve the visibility of the entire system. Currently, modules including Agent, DataProxy, TubeMQ, Sort-Standalone, etc. already support the above metrics, and the documentation of metrics output by each module is being sorted out.
Thanks to @shink, @luchunliang, @EMsnap, @gosonzhang and others for their contributions. For related PRs, please see INLONG-1712, [INLONG-1786] (https://github.com/apache/incubator-inlong/issues/1786), INLONG-1796, [INLONG-1827] (https://github.com/apache/incubator-inlong/issues/1827), INLONG-1851, [INLONG-1926] (https://github.com/apache/incubator-inlong/issues/1926).
3. Function extension of the modules
The Sort module adds support for Apache Doris storage and realizes the ability to load sorted data into Apache Doris, giving InLong one more storage option. In addition, in order to enrich the functions of the entire data access process, the Audit and Sort-Standalone modules have been added:
- The Audit module provides the ability to reconcile the entire process of data flow, and monitor the service quality of the system through data flow indicators;
- Sort-Standalone module is a non-Flink-based data sorting module. It adds lightweight data sorting capabilities to the system, facilitating the rapid construction and use of businesses.
The Audit and Sort-Standalone modules are still under development and will be released when the version is stable.
Thanks to @huzk8, @doleyzi, @luchunliang and others for their contributions, please refer to INLONG-1821, [INLONG-1738]( https: / /github.com/apache/incubator-inlong/issues/1738), INLONG-1889.
4. Official website document directory reconstruction
In addition to the improvement of functional modules in version 0.12.0, the official website structure and the use of documents have also been deeply adjusted, including the reconstruction of the document directory structure, supplementing and improving the function introduction of each module, adding document translation, and further improving the documentation of the InLong official website. Readability, to achieve quick search and easy reading. You can check the official website to understand this content. The document is still under construction. We welcome your valuable comments or suggestions.
Thanks to @bluewang, @dockerzhang, @healchow and others for their contributions, please refer to INLONG-1711, [INLONG-1740](https: //github.com/apache/incubator-inlong/issues/1740), INLONG-1802, [INLONG-1809](https: //github.com/apache/incubator-inlong/issues/1809), INLONG-1810, [INLONG-1815](https: //github.com/apache/incubator-inlong/issues/1815), INLONG-1822, [INLONG-1840](https: //github.com/apache/incubator-inlong/issues/1840), INLONG-1856, [INLONG-1861](https: //github.com/apache/incubator-inlong/issues/1861), INLONG-1867, [INLONG-1878](https: //github.com/apache/incubator-inlong/issues/1878), INLONG-1901, [INLONG-1939](https: //gith ub.com/apache/incubator-inlong/issues/1939).
5. Other features and bug fixes
For related content, please refer to Version Release Notes, which lists the detailed features of this version, Improvements, bug fixes, and specific contributors.
Apache InLong(incubating) follow-up planning
In subsequent versions, we will further enhance the capabilities of InLong to cover more usage scenarios, including:
- Support link for data access ClickHouse
- Support DB data collection
- The second stage full link indicator audit function