
Apache InLong recently released version 1.9.0, which closed about 200+ issues, including 2+ major features and 30+ optimizations. The main improvements include building observability capabilities and optimizing DataProxySDK-CPP. After the release of version 1.9.0, Apache InLong has enhanced its observability capabilities in areas such as end-to-end tracing, metric collection, access and visualization, and alerting. This addresses the need for rapid problem diagnosis and performance optimization during development and operations, improving the user experience for Apache InLong's operation and maintenance.
About Apache InLong
As the industry's first one-stop, full-scenario, open-source massive data integration framework, Apache InLong provides automatic, safe, reliable, and high-performance data transmission capabilities to facilitate businesses to build stream-based data analysis, modeling, and applications quickly. At present, InLong is widely used in various industries such as advertising, payment, social networking, games, artificial intelligence, etc., serving thousands of businesses, among which the scale of high-performance scene data exceeds 1 trillion lines per day, and the scale of high-reliability scene data exceeds 10 trillion lines per day.
The core keywords of InLong project positioning are "one-stop" and "massive data". For "one-stop", we hope to shield technical details, provide complete data integration and support services, and implement out-of-the-box; With its advantages, such as multi-cluster management, it can stably support larger-scale data volumes based on trillions of lines per day.
Overview of version 1.9.0
Apache InLong recently released version 1.9.0, which closed about 200+ issues, including 5+ major features and 30+ optimizations. The main work completed in this version includes building observability capabilities, optimizing DataProxy C++ SDK, optimizing DataProxy metadata configuration updates, adding command-line tools for TubeMQ, automatically switching write methods for Iceberg, and supporting resource migration between tenants in Manager. After the release of version 1.9.0, Apache InLong has enhanced its observability capabilities in areas such as end-to-end tracing, metric collection, access and visualization, and alerting. This addresses the need for rapid problem diagnosis and performance optimization during development and operations, while also improving the user experience for Apache InLong's operation and maintenance.
In addition, Apache InLong 1.9.0 includes a large number of other features, mainly including:
Agent module
- Support end-to-end log tracking and reporting, enhancing observability capabilities
- Remove metric reporting deregistration logic during TaskManager initialization
- Remove capacity limit for setting blacklist
- Optimize Agent's JVM parameters
DataProxy module
- Optimize metadata update logic
- Optimize DataProxy metric statistics
- Optimize retry logic after failed sending
Sort module
- Data synchronization supports audit metric reporting
- Iceberg supports dynamic switching between append and upsert modes
- When writing data to Kafka, support writing to different partitions based on custom fields
- PostgreSQL supports multi-concurrent reading
- Doris write supports automatic Schema changes
Manager module
- Support end-to-end log tracking and reporting, enhancing observability capabilities
- Support data targets such as Tencent CLS, Pulsar cluster, Iceberg, and StarRocks
- Support Iceberg and StarRocks as data sources on Flink 1.15
- Improve multi-tenant capabilities: including tenant status validation before deleting a tenant, OpenAPI support for tenant parameters, and multi-tenant configuration support for data sources
- ManagerClient supports paginated queries for data stream Source and Sink resources
Dashboard module
- Support management of Pulsar data clusters and support output to Pulsar
- Optimize the performance of tenant permission queries
- Improve the usability of the interface display
Audit module
- Add audit_tag information to distinguish between data sources and data targets
- Optimize audit Proxy log output
SDK module
- Optimize DataProxySDK-CPP, improving performance and reliability during network instability
- SortSDK supports parallel creation of cache layer consumption
- Optimize failure retry strategy for DataProxySDK-Java
TubeMQ module
- Add TubeMQ command-line tool
- TubeMQ Manager adds restart script
Others
- Add ASF DOAP file
- Add Mysql connector management image
- Optimize third-party dependencies to address security risks
1.9.0 Feature Introduction
Observability Capability Building
In the application process of Apache InLong, the following scenario requirements are often encountered:
- Locate the problematic code through detailed link call data (Tracing)
- Query and analyze the abnormal module and associated logs to find the core error information (Logs)
- Open the monitoring dashboard to find abnormal phenomena and locate the abnormal module through queries (Metrics)
- Discover anomalies through various preset alarms (Metrics/Logs)
In version 1.9.0, @ZhaoNiuniu has contributed to the complete observability capability building of InLong based on OpenTelemetry. OpenTelemetry provides flexible, convenient, and rich Span customization capabilities, such as adding custom attributes, adding events, etc. By embedding points in the core positions of the code, the data can be displayed in the backend UI. The entire solution mainly includes the following steps:
- The application pushes the Trace, Log, and Metric data collected through instrumentation to the otel collector using the otlp-exporter;
- The otel collector collects and converts the data, then exports it to Jaeger, Prometheus, and Elasticsearch;
- Grafana configures the three data sources for unified display, query, monitoring, and alerting.
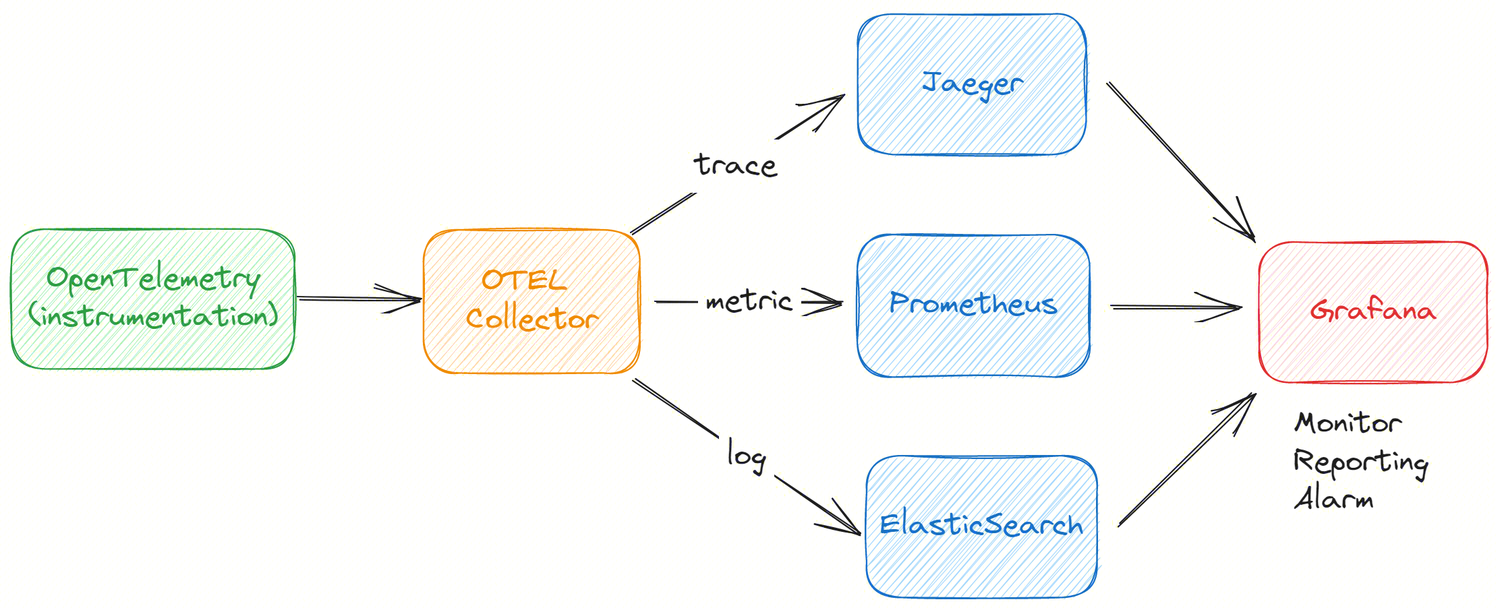
Thanks to @ZhaoNiuniu's contribution, see INLONG-8611 and INLONG-8799 for details.
Optimize DataProxy C++ SDK
The older version of DataProxy C++ SDK was developed based on the C language, which had limited extensibility. The use of the singleton pattern resulted in performance limitations, and the handling of failed sending scenarios was unreasonable, which could easily trigger coredump. Therefore, the SDK has been optimized with the following improvements:
- Adopt the C++ development mode, refactor DataProxy C++ SDK, no longer limited by the C language, enhancing the extensibility of the code;
- A single process supports multiple SDK instances, allowing horizontal scaling by adding SDK instances, breaking through performance limitations;
- Decouple data reception and data transmission, allowing separate configuration of the number of threads for receiving and sending, improving the SDK's scalability;
- Decouple the SDK's data packaging logic from the business thread, reducing the impact on the business thread while improving the packaging performance;
- Resolve the issue of the older version SDK causing coredump due to sending failures from the root.
With these optimizations, the DataProxy C++ SDK becomes more efficient, scalable, and reliable, providing better data processing capabilities for Apache InLong users.
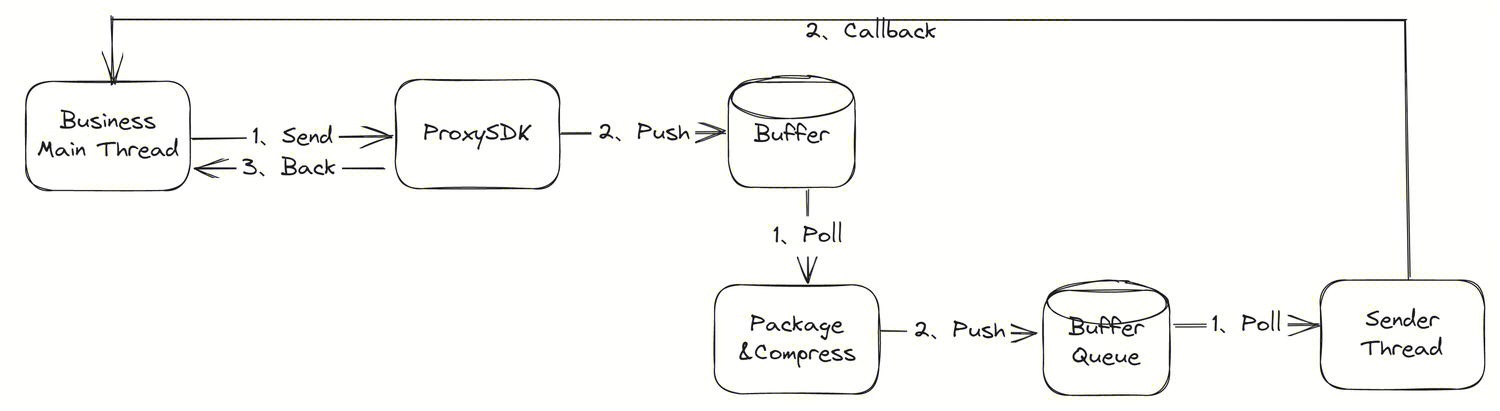
Thanks to @doleyzi's contribution, see INLONG-8747 for details.
Optimize metadata update logic of DataProxy
DataProxy fetches metadata configuration from Manager, but sometimes due to network issues, misoperations, or other reasons, DataProxy may obtain incorrect metadata configuration from Manager. In version 1.9.0, DataProxy has added a protection mechanism for metadata configuration updates, enhancing the reliability of Apache InLong in extreme scenarios. The logic of the metadata configuration update protection mechanism is as follows:
- When DataProxy receives a new metadata configuration from Manager, it first checks the configuration's validity, such as checking for null values, incorrect formats, etc., to ensure that the received configuration is correct and complete.
- DataProxy compares the new configuration with the current configuration. If there are no significant differences, it ignores the new configuration and continues using the current one. This helps avoid unnecessary updates and reduces the impact on the system.
- If the new configuration has significant differences from the current configuration, DataProxy will update its internal data structures and processing logic accordingly, ensuring that the system can adapt to the new configuration without causing errors or data loss.
- In case the new configuration causes errors or issues, DataProxy will roll back to the previous configuration and report the problem to Manager, allowing the system to maintain its stability and reliability.
By implementing this protection mechanism for metadata configuration updates, Apache InLong can better handle extreme scenarios and ensure the reliability of its data processing capabilities.
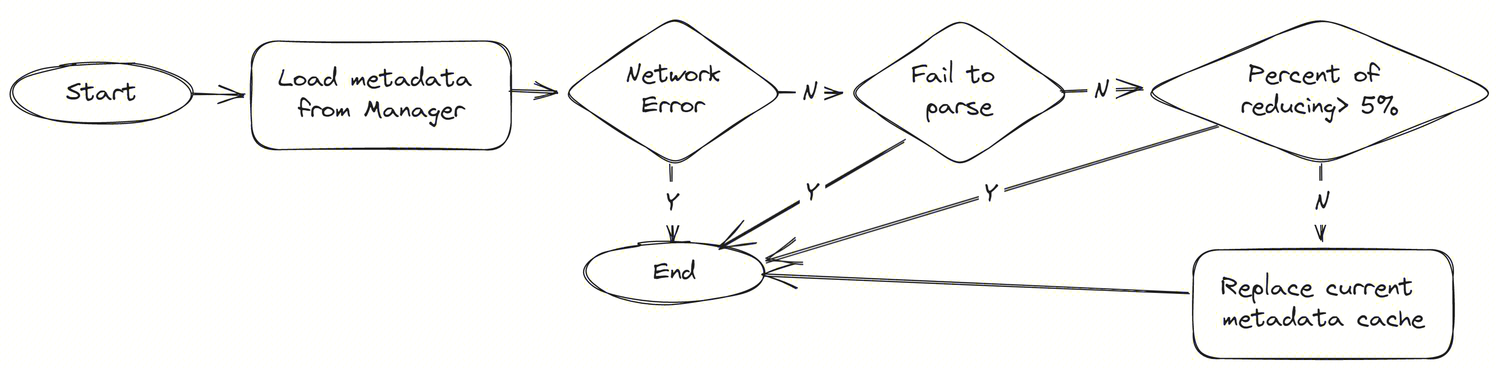
Thanks to @gosonzhang's contribution, see INLONG-8758 and INLONG-8899 for details.
TubeMQ command-line tool
To enable Apache InLong operations and maintenance personnel to perform various operations simply, quickly, and flexibly in terminal windows in server management and DevOps scenarios, TubeMQ provides command-line tools to manage topics, produce and consume messages, and manage consumer groups through command-line parameters or options. For detailed usage documentation, please refer to TubeMQ Command-line Tools. The main features include:
- Managing topics: creating, deleting, and querying topics, as well as setting topic attributes such as the number of partitions and replication factor.
- Producing messages: sending messages to specified topics, with support for custom message content, key, and partition.
- Consuming messages: consuming messages from specified topics and partitions, with support for specifying consumer groups and offsets.
- Managing consumer groups: creating, deleting, and querying consumer groups, as well as setting consumer group attributes such as rebalancing and offset management.
- Monitoring and statistics: collecting and displaying various statistics and metrics related to topics, producers, consumers, and consumer groups, helping users understand the system's performance and status.
By providing these command-line tools, Apache InLong allows operations and maintenance personnel to manage and operate TubeMQ more easily and efficiently in various scenarios.
$ bin/tubectl [options] [command] [command options]
$ bin/tubectl topic -h
$ bin/tubectl message produce
$ bin/tubectl message consume
$ bin/tubectl cgroup list
Thanks to @fancycoderzf's contribution, see INLONG-4972 for details.
Automatically switch write modes of Iceberg
Currently, the real-time synchronization from MySQL to Iceberg uses the upsert mode by default during the full data phase. The upsert implementation in Iceberg involves a delete operation followed by an add operation, with the delete operation resulting in the creation of a large number of delete files. This significantly impacts query efficiency. This optimization enables the task to use Append mode during the full data phase and automatically switch to Upsert mode during the incremental phase. The implementation involves the source carrying metadata fields in the data to determine which write mode to use in the Iceberg writer. When switching write modes, the data is refreshed, and the metadata fields are removed during the actual write operation.
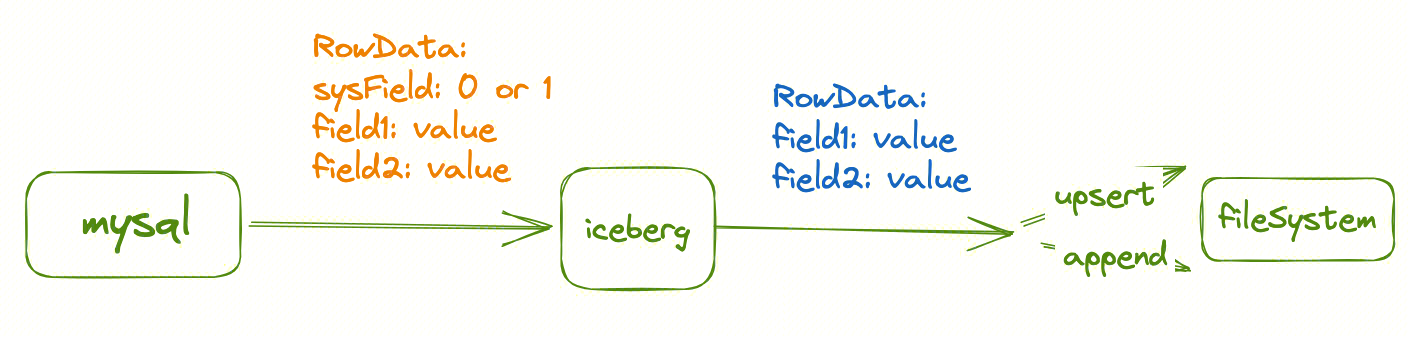
Thanks to @lordcheng10 and @Emsnap's contribution.
Manager support resource migration between tenants
After InLong supports multi-tenancy, InLong Groups upgraded from older versions will be defined under the public tenant, while newly created InLong Groups will be defined within the tenant under the user's name. This leads to users frequently switching between multiple tenants to use resources. This optimization supports the migration of InLong Groups between different tenants, while also validating and automatically creating corresponding cluster labels, data nodes, and other resources.

Thanks to @vernedeng's contribution.
Follow-up planning
In the 1.9.0 version, the community has also refactored the DataProxy C++ SDK, enriched the Flink 1.15 Connector, and improved data synchronization features. In subsequent versions, InLong will continue to enrich the Flink 1.15 Connector, enhance the scheduling capabilities of data synchronization, and improve the Agent's file collection capabilities. We look forward to more developers participating and contributing.