Kafka
概览
Kafka Load 节点支持写数据到 Kafka topics。 它支持以普通的方式写入数据和 Upsert 的方式写入数据。 upsert-kafka 连接器可以消费 changelog 流。它会将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。
支持的版本
| Load 节点 | Kafka 版本 |
|---|---|
| Kafka | 0.10+ |
依赖
为了设置 Kafka Load 节点, 下面提供了使用构建自动化工具(例如 Maven 或 SBT)和带有 Sort Connector JAR 包的 SQL 客户端的两个项目的依赖关系信息。
Maven 依赖
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-kafka</artifactId>
<version>${siteVariables.inLongVersion}</version>
</dependency>
如何创建 Kafka Load 节点
SQL API 用法
下面这个例子展示了如何用 Flink SQL 创建一个 Kafka Load 节点:
- 连接器是
kafka-inlong
-- 使用 Flink SQL 创建 Kafka 表 'kafka_load_node'
Flink SQL> CREATE TABLE kafka_load_node (
`id` INT,
`name` STRINTG
) WITH (
'connector' = 'kafka-inlong',
'topic' = 'user',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'format' = 'csv'
)
- 连接器是
upsert-kafka
-- 使用 Flink SQL 创建 Kafka 表 'kafka_load_node'
Flink SQL> CREATE TABLE kafka_load_node (
`id` INT,
`name` STRINTG,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka-inlong',
'topic' = 'user',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'csv',
'value.format' = 'csv'
)
InLong Dashboard 用法
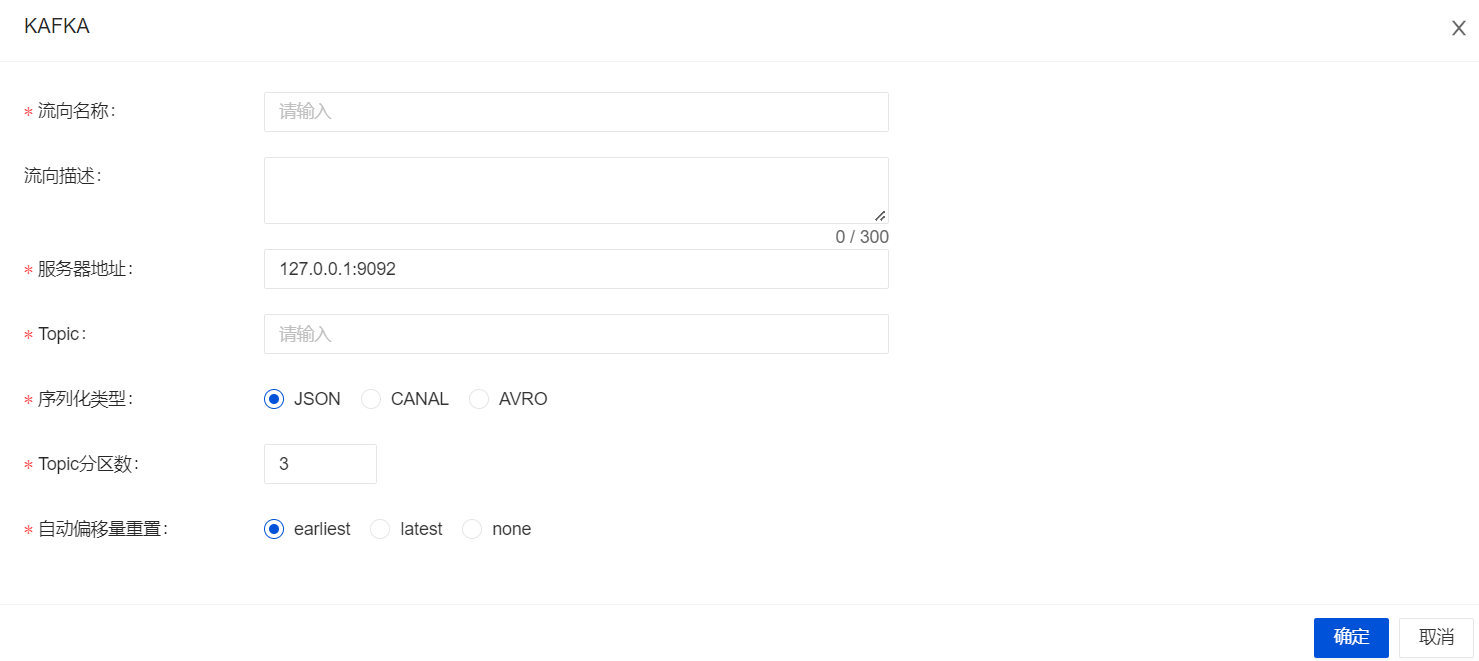
创建数据流时,数据流方向选择Kafka,点击“添加”进行配置。
InLong Manager Client 用法
将在未来支持此功能
Kafka Load 节点参数
| 参数 | 是否必选 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | 必选 | (none) | String | 指定要使用的连接器 1. Upsert Kafka 连接器使用: upsert-kafka-inlong 2. Kafka连接器使用: kafka-inlong |
| topic | 必选 | (none) | String | 当表用作 source 时读取数据的 topic 名。亦支持用分号间隔的 topic 列表,如 topic-1;topic-2。注意,对 source 表而言,topic 和 topic-pattern 两个选项只能使用其中一个。 |
| topic-pattern | 可选 | (none) | String | 动态 Topic 提取模式, 形如 ${VARIABLE_NAME}, 仅用于 Kafka 多 Sink 场景且当 format 为 raw 时有效。 |
| sink.multiple.format | 可选 | (none) | String | Kafka 原始数据的 Format, 目前仅支持 [canal-json|debezium-json] 仅用于 Kafka 多 Sink 场景且当 format 为 raw 时有效。 |
| properties.bootstrap.servers | 必选 | (none) | String | 逗号分隔的 Kafka broker 列表。 |
| properties.* | 可选 | (none) | String | 可以设置和传递任意 Kafka 的配置项。后缀名必须匹配在 Kafka 配置文档 中定义的配置键。Flink 将移除 "properties." 配置键前缀并将变换后的配置键和值传入底层的 Kafka 客户端。例如,你可以通过 properties.allow.auto.create.topics = false 来禁用 topic 的自动创建。但是某些配置项不支持进行配置,因为 Flink 会覆盖这些配置,例如 key.deserializer 和 value.deserializer。 |
| format | 对于 Kafka 必选 | (none) | String | 用来序列化或反序列化 Kafka 消息的格式。 请参阅 格式 页面以获取更多关于格式的细节和相关配置项。 注意:该配置项和 value.format 二者必需其一。 |
| key.format | 可选 | (none) | String | 用来序列化和反序列化 Kafka 消息键(Key)的格式。 请参阅 格式 页面以获取更多关于格式的细节和相关配置项。 注意:如果定义了键格式,则配置项 key.fields 也是必需的。 否则 Kafka 记录将使用空值作为键。 |
| key.fields | 可选 | [] | List<String> | 表结构中用来配置消息键(Key)格式数据类型的字段列表。默认情况下该列表为空,因此消息键没有定义。 列表格式为 field1;field2。 |
| key.fields-prefix | 可选 | (none) | String | 为所有消息键(Key)格式字段指定自定义前缀,以避免与消息体(Value)格式字段重名。默认情况下前缀为空。 如果定义了前缀,表结构和配置项 key.fields 都需要使用带前缀的名称。 当构建消息键格式字段时,前缀会被移除,消息键格式将会使用无前缀的名称。 请注意该配置项要求必须将 value.fields-include 配置为 EXCEPT_KEY。 |
| value.format | 必选 for upsert Kafka | (none) | String | 用于对 Kafka 消息中 value 部分序列化和反序列化的格式。支持的格式包括 csv、json、avro。请参考格式 页面以获取更多详细信息和格式参数。 |
| value.fields-include | 可选 | ALL | Enum Possible values: [ALL, EXCEPT_KEY] | 控制哪些字段应该出现在 value 中。可取值: ALL:消息的 value 部分将包含 schema 中所有的字段,包括定义为主键的字段。 EXCEPT_KEY:记录的 value 部分包含 schema 的所有字段,定义为主键的字段除外。 |
| sink.partitioner | 可选 | default | String | Flink partition 到 Kafka partition 的分区映射关系,可选值有: default:使用 Kafka 默认的分区器对消息进行分区。 fixed:每个 Flink partition 最终对应最多一个 Kafka partition。 round-robin:Flink partition 按轮循(round-robin)的模式对应到 Kafka partition。 raw-hash: 基于 sink.multiple.partition-pattern 提取值作 hash 以确定最终的分区, 仅用于 Kafka 多 Sink 场景且当 format 为 raw 时有效。只有当未指定消息的消息键时生效。自定义 FlinkKafkaPartitioner 的子类:例如 org.mycompany.MyPartitioner。请参阅 Sink 分区 以获取更多细节。 |
| sink.multiple.partition-pattern | 可选 | (none) | String | 动态 Partition 提取模式, 形如 ${VARIABLE_NAME}仅用于 Kafka 多 Sink 场景且当 format 为 raw、sink.partitioner 为 raw-hash 时有效。 |
| sink.semantic | 可选 | at-least-once | String | 定义 Kafka sink 的语义。有效值为 at-least-once,exactly-once 和 none。请参阅 一致性保证 以获取更多细节。 |
| sink.parallelism | 可选 | (none) | Integer | 定义 Kafka sink 算子的并行度。默认情况下,并行度由框架定义为与上游串联的算子相同。 |
| inlong.metric.labels | 可选 | (none) | String | inlong metric 的标签值,该值的构成为groupId={groupId}&streamId={streamId}&nodeId={nodeId}。 |
可用的元数据字段
支持为格式 canal-json-inlong写元数据。
参考 Kafka Extract Node 关于元数据的列表。
特征
支持动态 Schema 写入
动态 Schema 写入支持从数据中动态提取 Topic 和 Partition, 并写入到对应的 Topic
和 Partition。为了支持动态 Schema 写入,需要设置 Kafka 的 Format 格式为 raw,
同时需要设置上游数据的序列化格式(通过选项 sink.multiple.format
来设置, 目前仅支持 [canal-json|debezium-json])。
动态 Topic 提取
动态 Topic 提取即通过解析 Topic Pattern 并从数据中提取 Topic 。
为了支持动态提取 Topic, 需要设置选项 topic-pattern, Kafka Load Node 会解析 topic-pattern 作为最终的 Topic,
如果解析失败, 会写入通过 topic 设置的默认 Topic 中。topic-pattern 支持常量和变量,常量就是字符串常量,
变量是严格通过 ${VARIABLE_NAME} 来表示, 变量的取值来自于数据本身, 即可以是通过 sink.multiple.format
指定的某种 Format 的元数据字段, 也可以是数据中的物理字段。
关于 topic-parttern 的例子如下:
sink.multiple.format为canal-json:
上游数据为:
{
"data": [
{
"id": "111",
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": "5.18"
}
],
"database": "inventory",
"es": 1589373560000,
"id": 9,
"isDdl": false,
"mysqlType": {
"id": "INTEGER",
"name": "VARCHAR(255)",
"description": "VARCHAR(512)",
"weight": "FLOAT"
},
"old": [
{
"weight": "5.15"
}
],
"pkNames": [
"id"
],
"sql": "",
"sqlType": {
"id": 4,
"name": 12,
"description": 12,
"weight": 7
},
"table": "products",
"ts": 1589373560798,
"type": "UPDATE"
}
topic-pattern 为 {database}_${table}, 提取后的 Topic 为 inventory_products (database, table 为元数据字段)
topic-pattern 为 {database}_${table}_${id}, 提取后的 Topic 为 inventory_products_111 (database, table 为元数据字段, id 为物理字段)
sink.multiple.format为debezium-json:
上游数据为:
{
"before": {
"id": 4,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.18
},
"after": {
"id": 4,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.15
},
"source": {
"db": "inventory",
"table": "products"
},
"op": "u",
"ts_ms": 1589362330904,
"transaction": null
}
topic-pattern 为 {database}_${table}, 提取后的 Topic 为 inventory_products (source.db, source.table 为元数据字段)
topic-pattern 为 {database}_${table}_${id}, 提取后的 Topic 为 inventory_products_4 (source.db, source.table 为元数据字段, id 为物理字段)
动态 Partition 提取
动态 Partition 提取即通过解析 Partition Pattern 并从数据中提取 Partition, 这和动态 Topic 提取类似。
为了支持动态提取 Topic, 需要设置选项 sink.partitioner 为 raw-hash
和选项 sink.multiple.partition-pattern, Kafka Load Node 会解析 sink.multiple.partition-pattern
作为 Partition key, 并对 Partition key 进行 Hash 和对 Partition Size 取余以确定最终 Partition,
如果解析失败, 会返回 null 并执行 Kafka 默认的分区策略。sink.multiple.partition-pattern
支持常量、变量和主键,常量就是字符串常量, 变量是严格通过 ${VARIABLE_NAME} 来表示, 变量的取值来自于数据本身,
即可以是通过 sink.multiple.format 指定的某种 Format 的元数据字段, 也可以是数据中的物理字段,
主键是一种特殊的常量 PRIMARY_KEY, 基于某种 Format 的数据格式下来提取该条记录的主键值。
基于 PRIMARY_KEY 的 Kafka 动态 Partition 提取, 有一个限制, 即需要在数据中指定主键信息,
例如 Format 为 canal-json, 则其主键 Key 为 pkNames。另外由于 Format debezium-json 无主键的定义, 对此
我们约定 debezium-json 的主键 Key 也为 pkNames 且和其他元数据字段如 table、db 一样包含在 source中,
如果用到了按主键分区, 且 Format 为 debezium-json, 需要确保真实数据满足上述约定。
数据类型映射
Kafka 将消息键值以二进制进行存储,因此 Kafka 并不存在 schema 或数据类型。Kafka 消息使用格式配置进行序列化和反序列化,例如 csv,json,avro。 因此,数据类型映射取决于使用的格式。请参阅 格式 页面以获取更多细节。