Hudi
Overview
Apache Hudi (pronounced "hoodie") is a next-generation streaming data lake platform. Apache Hudi brings core warehouse and database functionality directly into the data lake. Hudi provides tables, transactions, efficient upserts/deletes, advanced indexing, streaming ingestion services, data clustering/compression optimizations, and concurrency while keeping data in an open source file format.
Supported Version
| Load Node | Version |
|---|---|
| Hudi | Hudi: 0.12+ |
Dependencies
Introduce sort-connector-hudi through Maven to build your own project.
Of course, you can also directly use the jar package provided by INLONG.
(sort-connector-hudi)
Maven dependency
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-hudi</artifactId>
<version>1.5.0</version>
</dependency>
How to create a Hudi Load Node
Usage for SQL API
The example below shows how to create a Hudi Load Node with Flink SQL Cli :
CREATE TABLE `hudi_table_name` (
id STRING,
name STRING,
uv BIGINT,
pv BIGINT
) WITH (
'connector' = 'hudi-inlong',
'path' = 'hdfs://127.0.0.1:90001/data/warehouse/hudi_db_name.db/hudi_table_name',
'uri' = 'thrift://127.0.0.1:8091',
'hoodie.database.name' = 'hudi_db_name',
'hoodie.table.name' = 'hudi_table_name',
'hoodie.datasource.write.recordkey.field' = 'id',
'hoodie.bucket.index.hash.field' = 'id',
-- compaction
'compaction.tasks' = '10',
'compaction.async.enabled' = 'true',
'compaction.schedule.enabled' = 'true',
'compaction.max_memory' = '3096',
'compaction.trigger.strategy' = 'num_or_time',
'compaction.delta_commits' = '5',
'compaction.max_memory' = '3096',
--
'hoodie.keep.min.commits' = '1440',
'hoodie.keep.max.commits' = '2880',
'clean.async.enabled' = 'true',
--
'write.operation' = 'upsert',
'write.bucket_assign.tasks' = '60',
'write.tasks' = '60',
'write.log_block.size' = '128',
--
'index.type' = 'BUCKET',
'metadata.enabled' = 'false',
'hoodie.bucket.index.num.buckets' = '20',
'table.type' = 'MERGE_ON_READ',
'clean.retain_commits' = '30',
'hoodie.cleaner.policy' = 'KEEP_LATEST_COMMITS'
);
Usage for InLong Dashboard
Configuration
When creating a data stream, select Hudi for the data stream direction, and click "Add" to configure it.
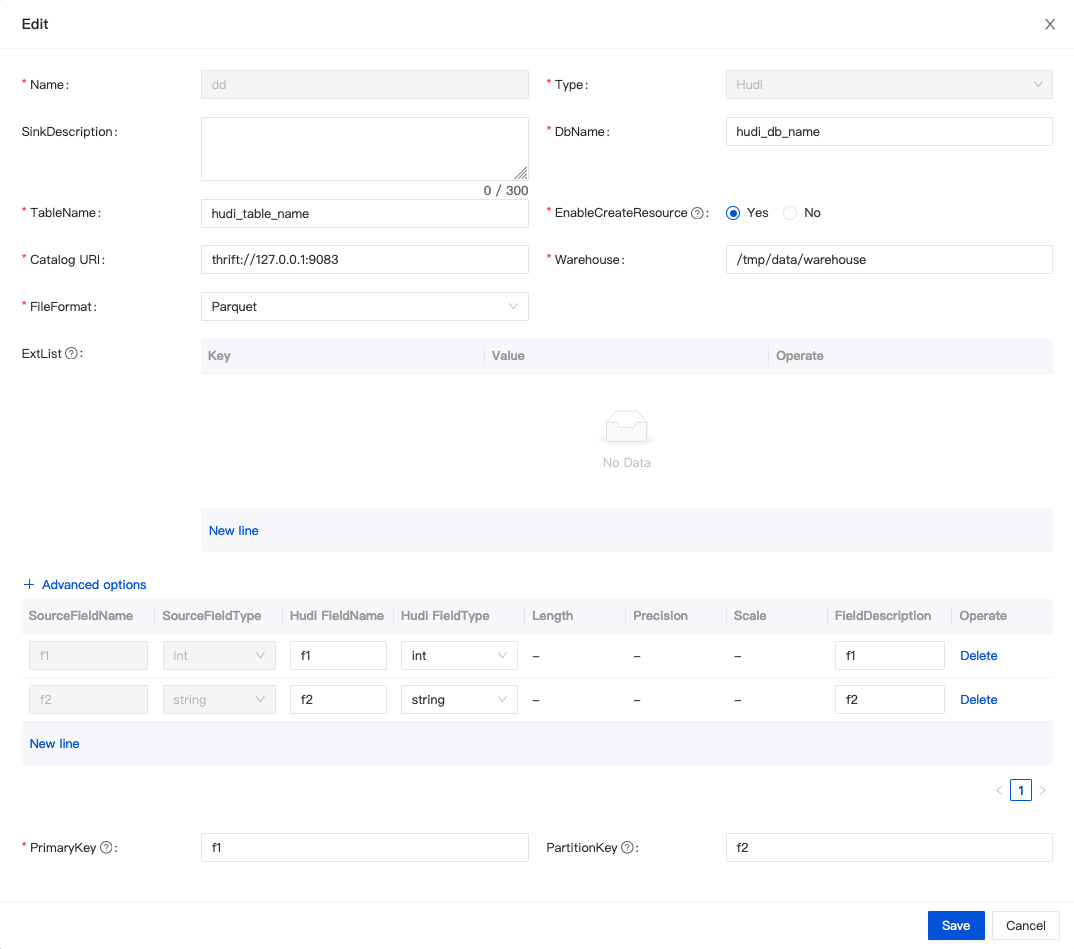
| Config Item | prop in DDL statement | remark |
|---|---|---|
DbName | hoodie.database.name | the name of database |
TableName | hudi_table_name | the name of table |
EnableCreateResource | - | If the library table already exists and does not need to be modified, select [Do not create], otherwise select [Create], and the system will automatically create the resource. |
Catalog URI | uri | The server uri of catalog |
Warehouse | - | The location where the hudi table is stored in HDFS In the SQL DDL, the path attribute is to splice the warehouse path with the name of db and table |
ExtList | - | The DDL attribute of the hudi table needs to be prefixed with 'ddl.' |
Advanced options>DataConsistency | - | Consistency semantics of Flink computing engine: EXACTLY_ONCE or AT_LEAST_ONCE |
PartitionFieldList | hoodie.datasource.write.partitionpath.field | partition field list |
PrimaryKey | hoodie.datasource.write.recordkey.field | primary key |
Usage for InLong Manager Client
TODO: It will be supported in the future.
Hudi Load Node Options
| Option | Required | Default | Type | Description |
|---|---|---|---|---|
| connector | required | (none) | String | Specify what connector to use, here should be 'hudi-inlong'. |
| uri | required | (none) | String | Metastore uris for hive sync |
| hoodie.database.name | optional | (none) | String | Database name that will be used for incremental query.If different databases have the same table name during incremental query, we can set it to limit the table name under a specific database |
| hoodie.table.name | optional | (none) | String | Table name that will be used for registering with Hive. Needs to be same across runs. |
| hoodie.datasource.write.recordkey.field | required | (none) | String | Record key field. Value to be used as the recordKey component of HoodieKey. Actual value will be obtained by invoking .toString() on the field value. Nested fields can be specified using the dot notation eg: a.b.c |
| hoodie.datasource.write.partitionpath.field | optional | (none) | String | Partition path field. Value to be used at the partitionPath component of HoodieKey. Actual value obtained by invoking .toString() |
| inlong.metric.labels | optional | (none) | String | Inlong metric label, format of value is groupId=xxgroup&streamId=xxstream&nodeId=xxnode. |
Data Type Mapping
| Hive type | Flink SQL type |
|---|---|
| char(p) | CHAR(p) |
| varchar(p) | VARCHAR(p) |
| string | STRING |
| boolean | BOOLEAN |
| tinyint | TINYINT |
| smallint | SMALLINT |
| int | INT |
| bigint | BIGINT |
| float | FLOAT |
| double | DOUBLE |
| decimal(p, s) | DECIMAL(p, s) |
| date | DATE |
| timestamp(9) | TIMESTAMP |
| bytes | BINARY |
| array | LIST |
| map | MAP |
| row | STRUCT |