Introduction
InLong (应龙) is a divine beast in Chinese mythology who guides the river into the sea, and it is regarded as a metaphor of the InLong system for reporting data streams.
About InLong
Apache InLong is a one-stop integration framework for massive data ,it provides automatic, safe, reliable, and high-performance data transmission capabilities to facilitate the construction of streaming-based data analysis, modeling, and applications. The Apache InLong project was originally called TubeMQ, focusing on high-performance, low-cost message queuing services. To further release the surrounding ecological capabilities of TubeMQ, the community upgraded the project to InLong, focusing on creating a one-stop integration framework for massive data. Apache InLong relies on 10 trillion-level data ingestion and processing capabilities to integrate the entire process of data collection, aggregation, storage, and sorting data processing. It is simple, flexible, stable, and reliable. The project was initially donated to the Apache incubator by the Tencent Big Data team in November 2019 and officially graduated as an Apache top-level project in June 2022. Currently, InLong is widely used in various industries such as advertising, payment, social networking, games, artificial intelligence, etc., to provide efficient and convenient customer services in multiple fields.
Features
Ease of Use
InLong is a SaaS-based service platform. Users can easily and quickly report, transfer, and distribute data by publishing and subscribing to data based on topics.
Stability & Reliability
InLong is derived from the actual online production environment. It delivers high-performance processing capabilities for 100 trillion-level data streams and highly reliable services for 100 billion-level data streams.
Comprehensive Features
InLong supports various types of data access methods and can be integrated with different types of Message Queue (MQ). It also provides real-time data extract, transform, and load (ETL) and sorting capabilities based on rules. InLong also allows users to plug features to extend system capabilities.
Service Integration
InLong provides unified system monitoring and alert services. It provides fine-grained metrics to facilitate data visualization. Users can view the running status of queues and topic-based data statistics in a unified data metric platform. Users can also configure the alert service based on their business requirements so that users can be alerted when errors occur.
Scalability
InLong adopts a pluggable architecture that allows you to plug modules into the system based on specific protocols. Users can replace components and add features based on their business requirements.
Architecture
- Standard
- Lightweight
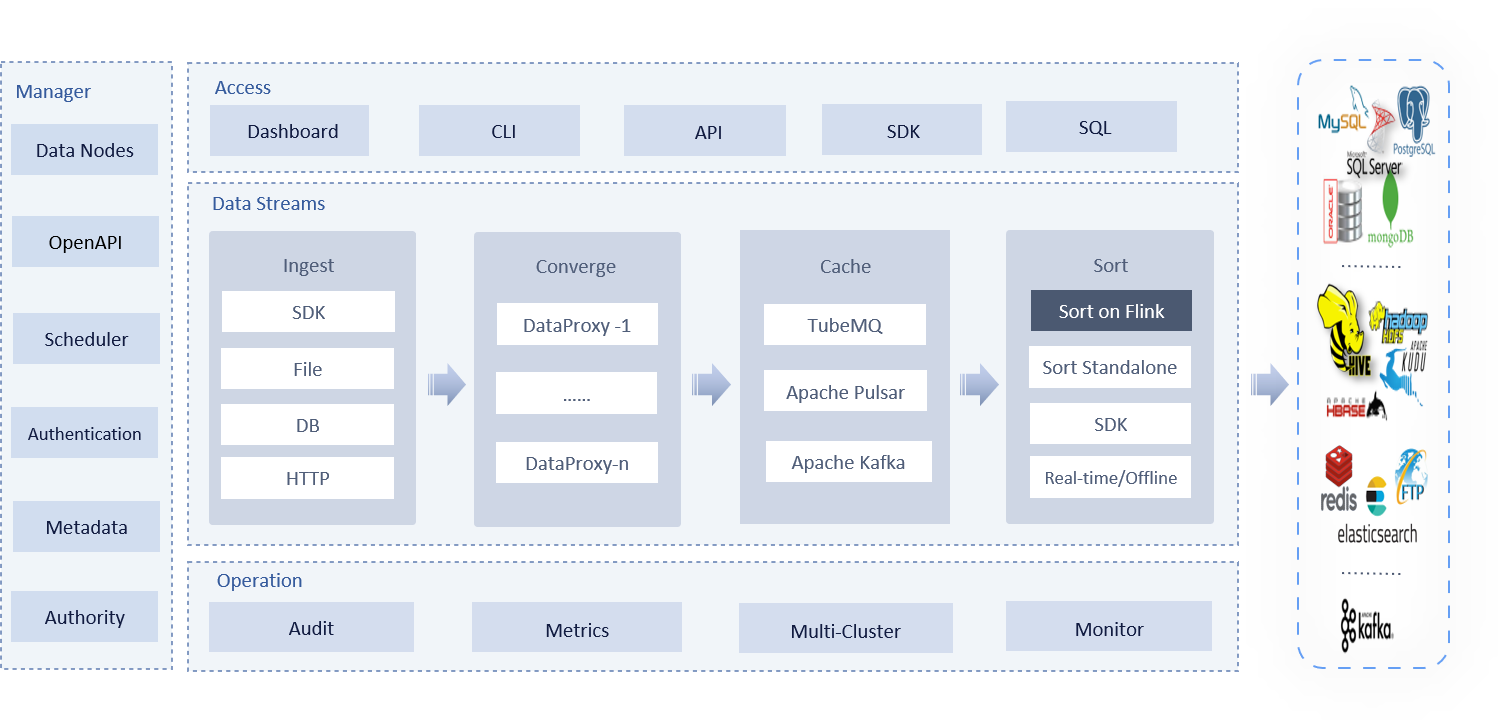
Modules
Apache InLong serves the entire life cycle from data collection to landing, and provides different processing modules according to different stages of data, including the next modules:
- inlong-agent, data collection services, including file collection, DB collection, etc.
- inlong-dataproxy, a Proxy component based on Flume-ng, supports data transmission blocking, placing retransmission, and has the ability to forward received data to different MQ (message queues).
- inlong-tubemq, Tencent's self-developed message queuing service, focuses on high-performance storage and transmission of massive data in big data scenarios and has a relatively good core advantage in mass practice and low cost.
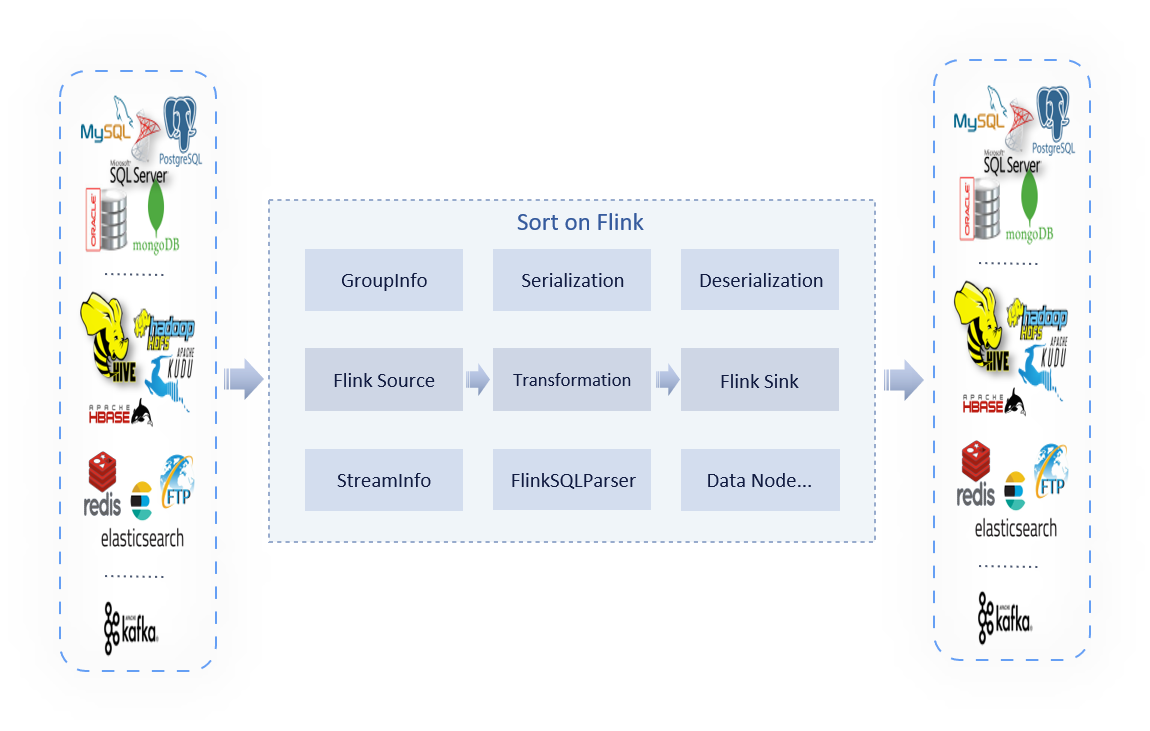
- inlong-sort, after consuming data from different MQ services, perform ETL processing, and then aggregate and write the data into Apache Hive, ClickHouse, Hbase, IceBerg, Hudi, etc.
- inlong-manager, provides complete data service management and control capabilities, including metadata, OpenAPI, task flow, authority, etc.
- inlong-dashboard, a front-end page for managing data access, simplifying the use of the entire InLong control platform.
- inlong-audit, performs real-time audit and reconciliation on the incoming and outgoing traffic of the Agent, DataProxy, and Sort modules of the InLong system.
Supported Data Nodes (Updating)
| Type | Name | Version | Architecture |
|---|---|---|---|
| Extract Node | Auto Push | None | Standard |
| File | None | Standard | |
| Kafka | 2.x | Lightweight, Standard | |
| MySQL | 5.6, 5.7, 8.0.x | Lightweight, Standard | |
| MongoDB | >= 3.6 | Lightweight, Standard | |
| MQTT | >= 3.1 | Standard | |
| Oracle | 11,12,19 | Lightweight | |
| PostgreSQL | 9.6, 10, 11, 12 | Lightweight, Standard | |
| Pulsar | 2.8.x | Lightweight | |
| Redis | 2.6.x | Standard | |
| SQLServer | 2012, 2014, 2016, 2017, 2019 | Lightweight, Standard | |
| Load Node | Auto Consumption | None | Standard |
| Hive | 1.x, 2.x, 3.x | Lightweight, Standard | |
| Iceberg | 0.12.x | Lightweight, Standard | |
| ClickHouse | 20.7+ | Lightweight, Standard | |
| Kafka | 2.x | Lightweight, Standard | |
| HBase | 2.2.x | Lightweight, Standard | |
| PostgreSQL | 9.6, 10, 11, 12 | Lightweight, Standard | |
| Oracle | 11, 12, 19 | Lightweight, Standard | |
| MySQL | 5.6, 5.7, 8.0.x | Lightweight, Standard | |
| TDSQL-PostgreSQL | 10.17 | Lightweight, Standard | |
| Greenplum | 4.x, 5.x, 6.x | Lightweight, Standard | |
| Elasticsearch | 6.x, 7.x | Lightweight, Standard | |
| SQLServer | 2012, 2014, 2016, 2017, 2019 | Lightweight, Standard | |
| Doris | >= 0.13 | Lightweight, Standard | |
| StarRocks | >= 2.0 | Lightweight, Standard | |
| HDFS | 2.x, 3.x | Lightweight, Standard |