Overview
InLong Agent is a collection tool that supports multiple types of data sources, and is committed to achieving stable and efficient data collection functions between multiple heterogeneous data sources including File, SQL, Binlog, Metrics, etc.
Design Concept
In order to solve the problem of data source diversity, InLong-agent abstracts multiple data sources into a unified source concept, and abstracts sinks to write data. When you need to access a new data source, you only need to configure the format and reading parameters of the data source to achieve efficient reading.
InLong-Agent Architecture
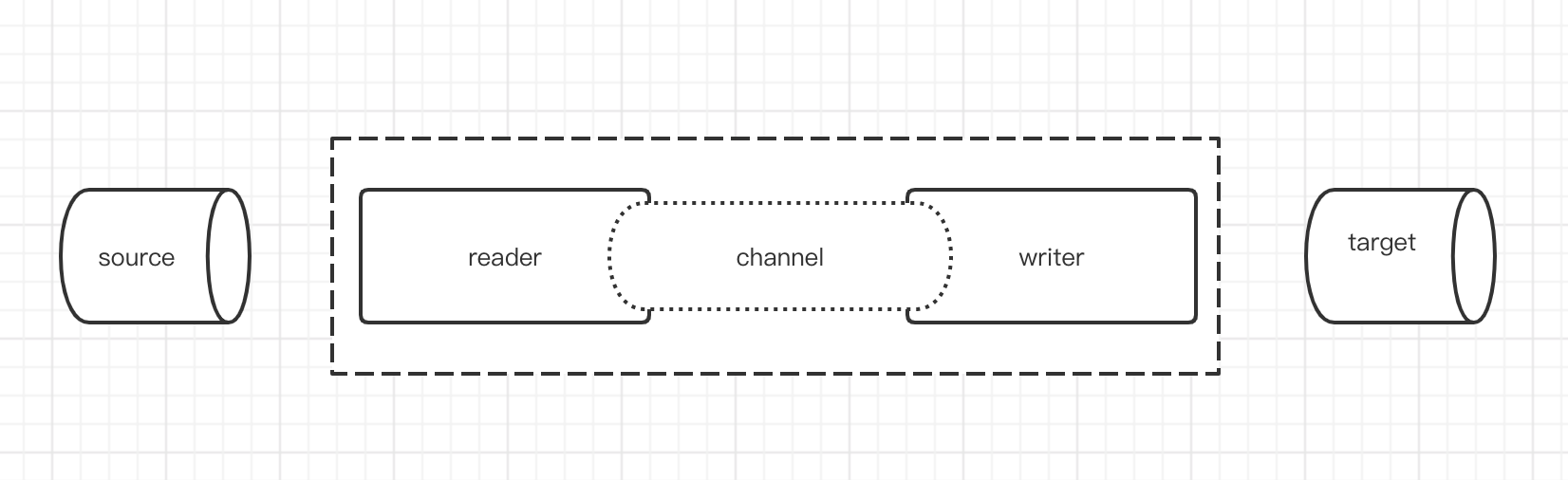
The InLong Agent task is used as a data acquisition framework, constructed with a channel + plug-in architecture. Read and write the data source into a reader/writer plug-in, and then into the entire framework.
- Reader: Reader is the data collection module, responsible for collecting data from the data source and sending the data to the channel.
- Writer: Writer is a data writing module, which reuses data continuously to the channel and writes the data to the destination.
- Channel: The channel used to connect the reader and writer, and as the data transmission channel of the connection, which realizes the function of data reading and monitoring
Different kinds of agent
File
File collection includes the following functions:
User-configured path monitoring, able to monitor the created file information Directory regular filtering, support YYYYMMDD+regular expression path configuration Breakpoint retransmission, when InLong-Agent restarts, it can automatically re-read from the last read position to ensure no reread or missed reading.
File options
| Parameter | Required | Default value | Type | Description |
|---|---|---|---|---|
| pattern | required | (none) | String | File pattern. For example: /root/[*].log |
| timeOffset | optional | (none) | String | File name includes time, for example: YYYYMMDDHH YYYY represents the year, MM represents the month, DD represents the day, and HH represents the hour, *** is any character. '1m' means one minute after, '-1m' means one minute before. '1h' means one hour after, '-1h' means one hour before. '1d' means one day after, '-1d' means one day before. |
| collectType | optional | FULL | String | FULL is all file. INCREMENT is the newly created file after start task. |
| lineEndPattern | optional | '\n' | String | Line of file end pattern. |
| contentCollectType | optional | FULL | String | Collect data of file content. |
| envList | optional | (none) | String | File needs to collect environment information, for example: kubernetes. |
| dataContentStyle | optional | (none) | String | Type of data result for column separator. Json format, set this parameter to json. CSV format, set this parameter to a custom separator: , | : |
| dataSeparator | optional | (none) | String | Column separator of data source. |
| monitorStatus | optional | (none) | Integer | Monitor switch, 1 true and 0 false. Batch data is 0,real time data is 1. |
| monitorInterval | optional | (none) | Long | Monitor interval for file. |
| monitorExpire | optional | (none) | Long | Monitor expire time and the time in milliseconds. |
SQL
This type of data refers to the way it is executed through SQL SQL regular decomposition, converted into multiple SQL statements Execute SQL separately, pull the data set, the pull process needs to pay attention to the impact on mysql itself The execution cycle, which is generally executed regularly
Binlog
This type of collection reads binlog and restores data by configuring mysql slave Need to pay attention to multi-threaded parsing when binlog is read, and multi-threaded parsing data needs to be labeled in order The code is based on the old version of dbsync, the main modification is to change the sending of tdbus-sender to push to agent-channel for integration