ClickHouse
Overview
The ClickHouse Load Node supports to write data into ClickHouse database. This document describes how to set up the ClickHouse Load
Node to run SQL queries against ClickHouse database.
Supported Version
| Load Node | Driver | Group Id | Artifact Id | JAR |
|---|---|---|---|---|
| ClickHouse | ClickHouse | ru.yandex.clickhouse | clickhouse-jdbc | Download |
Dependencies
In order to set up the ClickHouse Load Node, the following provides dependency information for both projects using a
build automation tool (such as Maven or SBT) and SQL Client with Sort Connectors JAR bundles.
Maven dependency
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-jdbc</artifactId>
<version>1.7.0</version>
</dependency>
How to create a ClickHouse Load Node
Usage for SQL API
-- MySQL extract node
CREATE TABLE `mysql_extract_table`(
PRIMARY KEY (`id`) NOT ENFORCED,
`id` BIGINT,
`name` STRING,
`age` INT
) WITH (
'connector' = 'mysql-cdc-inlong',
'url' = 'jdbc:mysql://localhost:3306/read',
'username' = 'inlong',
'password' = 'inlong',
'table-name' = 'user'
)
-- ClickHouse load node
CREATE TABLE `clickhouse_load_table`(
PRIMARY KEY (`id`) NOT ENFORCED,
`id` BIGINT,
`name` STRING,
`age` INT
) WITH (
'connector' = 'jdbc-inlong',
'dialect-impl' = 'org.apache.inlong.sort.jdbc.dialect.ClickHouseDialect',
'url' = 'jdbc:clickhouse://localhost:8123/demo',
'username' = 'inlong',
'password' = 'inlong',
'table-name' = 'demo.user'
)
-- write data into ClickHouse
INSERT INTO clickhouse_load_table
SELECT id, name , age FROM mysql_extract_table;
Usage for InLong Dashboard
When creating a data flow, select ClickHouse for the data stream direction, and click "Add" to configure it.
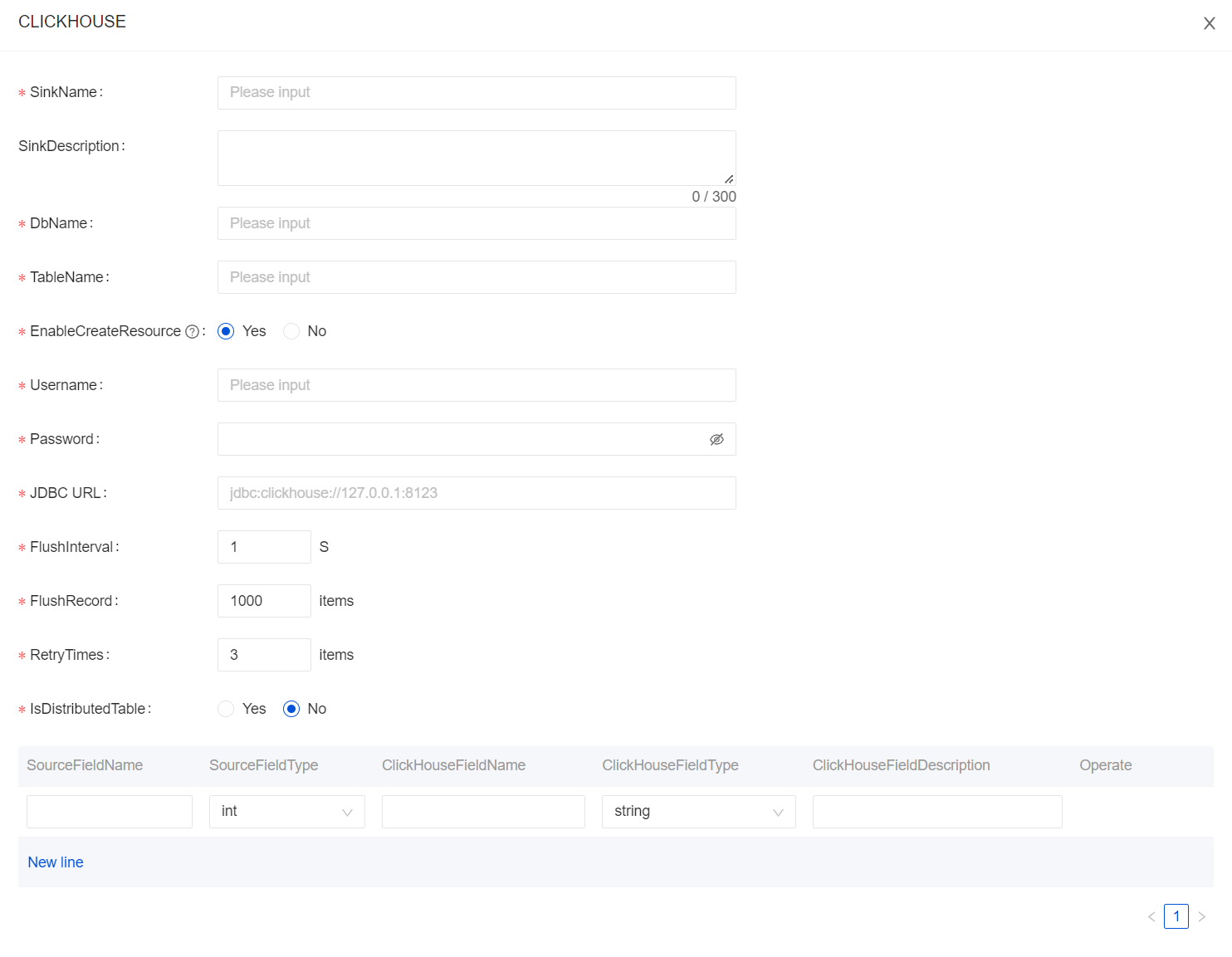
Usage for InLong Manager Client
TODO: It will be supported in the future.
ClickHouse Load Node Options
| Option | Required | Default | Type | Description |
|---|---|---|---|---|
| connector | required | (none) | String | Specify what connector to use, here should be 'jdbc-inlong'. |
| url | required | (none) | String | The JDBC database url. |
| dialect-impl | required | (none) | String | org.apache.inlong.sort.jdbc.dialect.ClickHouseDialect |
| table-name | required | (none) | String | The name of JDBC table to connect, for example database.tableName |
| driver | optional | (none) | String | The class name of the JDBC driver to use to connect to this URL, if not set, it will automatically be derived from the URL. |
| username | optional | (none) | String | The JDBC user name. 'username' and 'password' must both be specified if any of them is specified. |
| password | optional | (none) | String | The JDBC password. |
| connection.max-retry-timeout | optional | 60s | Duration | Maximum timeout between retries. The timeout should be in second granularity and shouldn't be smaller than 1 second. |
| sink.buffer-flush.max-rows | optional | 100 | Integer | The max size of buffered records before flush. Can be set to zero to disable it. |
| sink.buffer-flush.interval | optional | 1s | Duration | The flush interval mills, over this time, asynchronous threads will flush data. Can be set to '0' to disable it. Note, 'sink.buffer-flush.max-rows' can be set to '0' with the flush interval set allowing for complete async processing of buffered actions. |
| sink.max-retries | optional | 3 | Integer | The max retry times if writing records to database failed. |
| sink.parallelism | optional | (none) | Integer | Defines the parallelism of the JDBC sink operator. By default, the parallelism is determined by the framework using the same parallelism of the upstream chained operator. |
| sink.ignore.changelog | optional | false | Boolean | Ignore all RowKind, ingest them as INSERT. |
| inlong.metric.labels | optional | (none) | String | Inlong metric label, format of value is groupId={groupId}&streamId={streamId}&nodeId={nodeId}. |
Data Type Mapping
| ClickHouse type | Flink SQL type |
|---|---|
| String | CHAR |
| String IP UUID | VARCHAR |
| String EnumL | STRING |
| UInt8 | BOOLEAN |
| FixedString | BYTES |
| Decimal Int128 Int256 UInt64 UInt128 UInt256 | DECIMAL |
| Int8 | TINYINT |
| Int16 UInt8 | SMALLINT |
| Int32 UInt16 Interval | INTEGER |
| Int64 UInt32 | BIGINT |
| Float32 | FLOAT |
| Date | DATE |
| DateTime | TIME |
| DateTime | TIMESTAMP |
| DateTime | TIMESTAMP_LTZ |
| Int32 | INTERVAL_YEAR_MONTH |
| Int64 | INTERVAL_DAY_TIME |
| Array | ARRAY |
| Map | MAP |
| Not supported | ROW |
| Not supported | MULTISET |
| Not supported | RAW |