Offline Sync Connector Extension
Overview
Apache InLong is a powerful data synchronization tool that supports both real-time and offline synchronization, relying on Flink as its underlying engine. Through a unified Flink SQL API, users can handle both types of data synchronization tasks using the same code.
The difference between the two is that real-time synchronization uses Flink Streaming to implement data synchronization, while offline synchronization uses Flink Batch for data synchronization. In practical use, users can choose the appropriate synchronization method based on their needs..
This article describes how to extend offline synchronization connector plugins and how to extend third-party scheduling services.
Offline connector extension
Offline synchronization, like real-time synchronization, mainly consists of two parts: Source and Sink. The biggest difference lies in whether the Source is bounded:
- The Source for real-time synchronization is unbounded.
- The Source for offline synchronization is bounded.
Bounded means that the offline data source has a clear start and end, typically using batch processing for offline data synchronization. The offline data source reuses the Flink Connector from real-time synchronization and adds the property of whether the Source is bounded, while the implementation of the Sink is consistent with that of real-time synchronization.
Flink's Source provides interfaces to set data boundaries:
/**
* Get the boundedness of this source.
*
* @return the boundedness of this source.
*/
Boundedness getBoundedness();
Boundedness is an enumeration type with two values: BOUNDED and CONTINUOUS_UNBOUNDED.
@Public
public enum Boundedness {
/**
* A BOUNDED stream is a stream with finite records.
*/
BOUNDED,
/**
* A CONTINUOUS_UNBOUNDED stream is a stream with infinite records.
*/
CONTINUOUS_UNBOUNDED
}
Using Pulsar Source as an example, describe how to set the boundedness property for the Pulsar Source.
Data source boundaries
lowerBound: Represents the starting position of the boundary.
upperBound: Represents the ending position of the boundary.
boundaryType: Indicates the type of boundary, currently supporting two types: TIME and OFFSET.
public class Boundaries {
public String lowerBound;
public String upperBound;
public BoundaryType boundaryType;
}
The boundary information is carried by the ExtractNode, which corresponds to the Source in Flink.
public abstract class ExtractNode implements Node {
public void fillInBoundaries(Boundaries boundaries) {
Preconditions.checkNotNull(boundaries, "boundaries is null");
// every single kind of extract node should provide the way to fill in boundaries individually
}
}
Setting Boundaries for the Source
In PulsarExtractNode, the Boundaries information will be configured into the relevant parameters of the Pulsar Connector.:
@Override
public void fillInBoundaries(Boundaries boundaries) {
super.fillInBoundaries(boundaries);
BoundaryType boundaryType = boundaries.getBoundaryType();
String lowerBoundary = boundaries.getLowerBound();
String upperBoundary = boundaries.getUpperBound();
if (Objects.requireNonNull(boundaryType) == BoundaryType.TIME) {
// set time boundaries
sourceBoundaryOptions.put("source.start.publish-time", lowerBoundary);
sourceBoundaryOptions.put("source.stop.at-publish-time", upperBoundary);
og.info("Filled in source boundaries options");
} else {
log.warn("Not supported boundary type: {}", boundaryType);
}
}
These parameters will be recognized by the PulsarSource, and during the initialization of the PulsarSource, a BoundedStopCursor will be set for the Source.
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext context) {
PulsarDeserializationSchema<RowData> deserializationSchema =
deserializationSchemaFactory.createPulsarDeserialization(context);
PulsarSourceBuilder<RowData> sourceBuilder = PulsarSource.builder();
sourceBuilder
.setTopics(topics)
.setStartCursor(startCursor)
.setDeserializationSchema(deserializationSchema)
.setProperties(properties);
if (!(stopCursor instanceof NeverStopCursor)) {
// 设置 stop cursor
sourceBuilder.setBoundedStopCursor(stopCursor);
} else {
sourceBuilder.setUnboundedStopCursor(stopCursor);
}
return SourceProvider.of(sourceBuilder.build());
}
If a BoundedStopCursor is configured, the Source's boundedness property will be set to Boundedness.BOUNDED.
public PulsarSourceBuilder<OUT> setBoundedStopCursor(StopCursor stopCursor) {
this.boundedness = Boundedness.BOUNDED;
this.stopCursor = checkNotNull(stopCursor);
return this;
}
This way, the Flink engine can recognize that this is a bounded Source, allowing it to process data using a batch approach.
Offline Sync Scheduling
Offline synchronization is based on Flink batch jobs and can be scheduled at regular intervals. Each Flink batch job is triggered by the scheduling system. InLong has a built-in scheduling system based on Quartz, which supports the scheduling of offline tasks.
The overall process of offline synchronization task scheduling is illustrated in the following diagram:
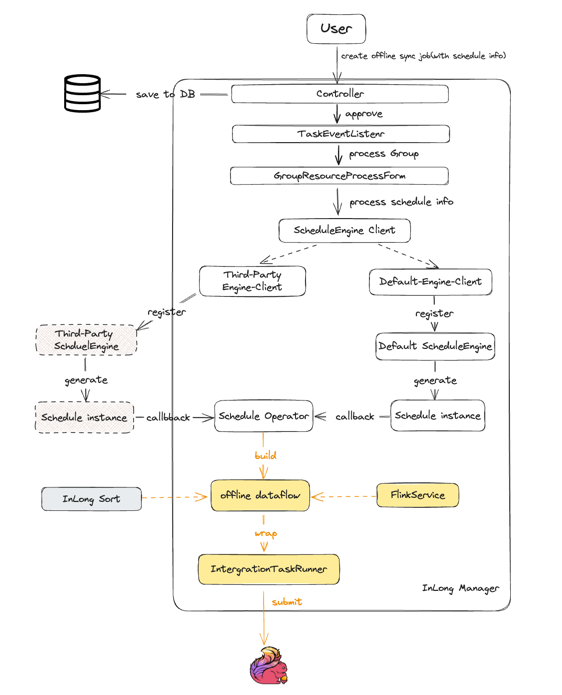
- The user creates an offline synchronization task
- After task approval, the task will be registered with the scheduling system via ScheduleClient.
- The scheduling service will periodically generate scheduling instances based on the configuration information.
- The scheduling instance will callback to InLong's Schedule Operator, initiating a task execution. The callback will carry detailed task information, including GroupId, StreamId, task start and end boundaries, and other parameters.
- The Schedule Operator will create a Flink Job based on the task's detailed information and submit it to the Flink cluster for execution.
Scheduling Engine Expansion
InLong's offline scheduling capability supports third-party scheduling systems. Next, we will introduce how to expand scheduling capabilities.
Scheduling Task Registration
ScheduleClient is the client for scheduling task registration, allowing users to register tasks with the scheduling system.
The ScheduleClient selects the scheduling engine based on the engineType in ScheduleInfo, and users can extend scheduling capabilities by implementing the ScheduleEngineClient interface.
public interface ScheduleEngineClient {
/**
* Check whether scheduleEngine type is matched.
* */
boolean accept(String engineType);
/**
* Register schedule to schedule engine.
* @param scheduleInfo schedule info to register
* */
boolean register(ScheduleInfo scheduleInfo);
/**
* Un-register schedule from schedule engine.
*
* @param groupId schedule info to unregister
*/
boolean unregister(String groupId);
/**
* Update schedule from schedule engine.
* @param scheduleInfo schedule info to update
* */
boolean update(ScheduleInfo scheduleInfo);
}
ScheduleEngineClient provides the capability to register, unregister, and update scheduling tasks, allowing users to implement these interfaces according to their needs.
Scheduling Task Execution
The execution of scheduling tasks relies on the scheduling service, which periodically generates scheduling instances based on the scheduling configuration. It then callbacks to InLong's Schedule Operator to initiate a task execution.
For example, using the built-in Quartz scheduling service, we can demonstrate how the scheduling system periodically triggers offline synchronization tasks.
public interface ScheduleEngine {
/**
* Start schedule engine.
* */
void start();
/**
* Handle schedule register.
* @param scheduleInfo schedule info to register
* */
boolean handleRegister(ScheduleInfo scheduleInfo);
/**
* Handle schedule unregister.
* @param groupId group to un-register schedule info
* */
boolean handleUnregister(String groupId);
/**
* Handle schedule update.
* @param scheduleInfo schedule info to update
* */
boolean handleUpdate(ScheduleInfo scheduleInfo);
/**
* Stop schedule engine.
* */
void stop();
}
QuartzScheduleEngine provides a Scheduler that offers capabilities for starting, stopping, registering, unregistering, and updating scheduling tasks in response to requests from ScheduleEngineClient.
Currently, QuartzScheduleEngine supports periodic scheduling based on scheduling cycle configurations and crontab expressions. Each periodic scheduling instance includes trigger time, cycle, and other relevant information, which is used to initiate InLong data synchronization tasks.
Each scheduling instance corresponds to a QuartzOfflineSyncJob, which sends an OfflineJobRequest to the Manager.
public class OfflineJobRequest {
@ApiModelProperty("Inlong Group ID")
@NotNull
private String groupId;
@ApiModelProperty("Source boundary type, TIME and OFFSET are supported")
@NotNull
private String boundaryType;
@ApiModelProperty("The lower bound for bounded source")
@NotNull
private String lowerBoundary;
@ApiModelProperty("The upper bound for bounded source")
@NotNull
private String upperBoundary;
}
OfflineJobRequest includes parameters such as GroupId, StreamId, and the task's start and end boundaries.
When extending third-party scheduling engines, users also need to construct OfflineJobRequest within the scheduling instance and send task execution requests to the Manager.
Summary
This article primarily describes methods for extending offline data synchronization capabilities, including how to enhance offline synchronization based on real-time data sources and how to support third-party scheduling engines.