MySQL-CDC
概述
MySQL Extract 节点允许从 MySQL 数据库中读取快照数据和增量数据。本文档介绍如何设置 MySQL Extract 节点以对 MySQL 数据库运行 SQL 查询。
支持的版本
| Extract 节点 | 版本 | Driver |
|---|---|---|
| MySQL-CDC | MySQL: 5.6, 5.7, 8.0.x RDS MySQL: 5.6, 5.7, 8.0.x PolarDB MySQL: 5.6, 5.7, 8.0.x Aurora MySQL: 5.6, 5.7, 8.0.x MariaDB: 10.x PolarDB X: 2.0.1 | JDBC Driver: 8.0.21 |
依赖
为了设置 MySQL Extract 节点,下表提供了使用构建自动化工具(例如 Maven 或 SBT)和带有 Sort Connectors JAR 包的 SQL 客户端的两个项目的依赖关系信息。
Maven 依赖
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-mysql-cdc</artifactId>
<version>1.6.0</version>
</dependency>
连接 MySQL 数据库还需要 MySQL 驱动程序依赖项。请下载mysql-connector-java-8.0.21.jar 并将其放入 FLINK_HOME/lib/。
设置 MySQL 服务器
你必须定义一个对 Debezium MySQL 连接器监控的所有数据库具有适当权限的 MySQL 用户。
- 创建 MySQL 用户:
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
- 向用户授予所需的权限:
mysql> GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
注意: 启用 scan.incremental.snapshot.enabled 时不再需要 RELOAD 权限(默认启用)。
- 刷新用户的权限:
mysql> FLUSH PRIVILEGES;
查看更多关于权限说明。
注意事项
为每个 Reader 设置一个不同的 SERVER ID
每一个读取 Binlog 的 MySQL 数据库客户端都应该有一个唯一的 Id,称为 Server Id。 MySQL 服务器将使用此 Id 来维护网络连接和 Binlog 位置。因此,如果不同的作业共享相同的服务器 Id,可能会导致从错误的 Binlog 位置读取。
因此,建议通过 [SQL Hints](https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/sql/hints. html),
例如假设源并行度为 4,那么我们可以使用 SELECT * FROM source_table /*+ OPTIONS('server-id'='5401-5404') */ ; 为 4 个 Source Reader 中的每一个分配唯一的服务器 Id。
设置 MySQL 会话超时
当为大型数据库制作初始一致快照时,您建立的连接可能会在读取表时超时。您可以通过在 MySQL 配置文件中配置 interactive_timeout 和 wait_timeout 来防止这种行为。
interactive_timeout:服务器在关闭交互式连接之前等待其活动的秒数。请参阅 MySQL 文档。wait_timeout:服务器在关闭非交互式连接之前等待其活动的秒数。请参阅 MySQL 文档。
如何创建一个 MySQL Extract 节点
SQL API 用法
下面这个例子展示了如何用 Flink SQL 创建一个 MySQL Extract 节点:
-- 设置 Checkpoint 为 3000 毫秒
Flink SQL> SET 'execution.checkpointing.interval' = '3s';
Flink SQL> CREATE TABLE mysql_extract_node (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc-inlong',
'hostname' = 'YourHostname',
'port' = '3306',
'username' = 'YourUsername',
'password' = 'YourPassword',
'database-name' = 'YourDatabaseName',
'table-name' = 'YourTableName');
Flink SQL> SELECT * FROM mysql_extract_node;
InLong Dashboard 用法
Choose the
BINLOGData Source
Configure the MySQL Source
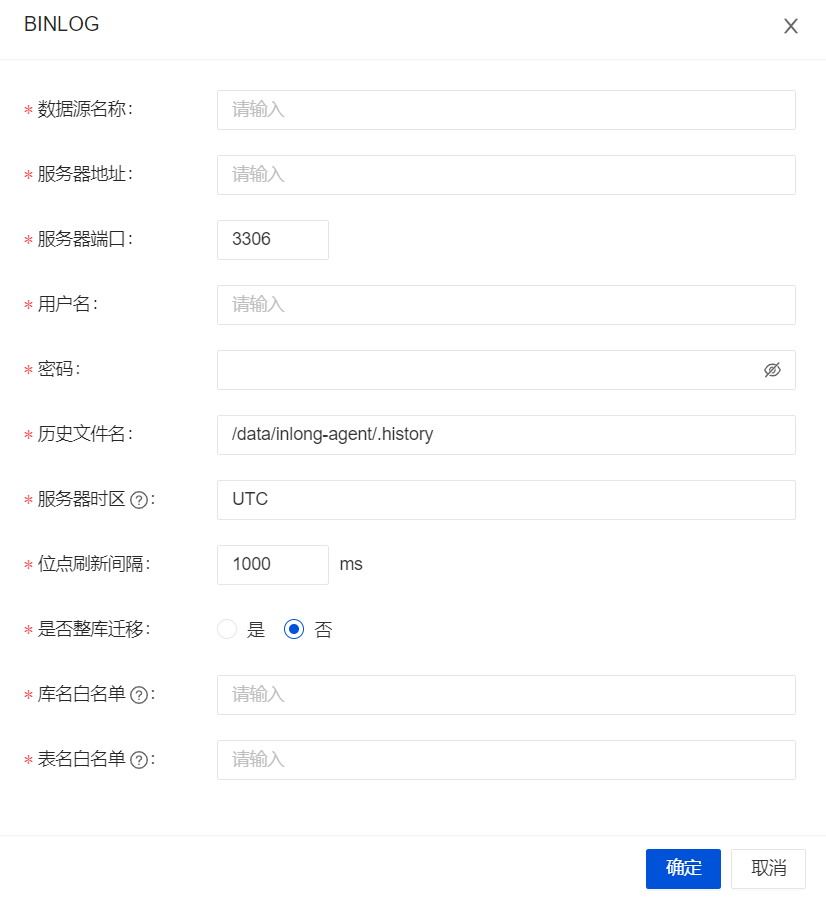
InLong Manager Client 用法
TODO: 将在未来支持此功能。
MySQL Extract 节点参数
| 参数 | 是否必须 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | required | (none) | String | 指定要使用的连接器,这里应该是 'mysql-cdc-inlong'。 |
| hostname | required | (none) | String | MySQL 数据库服务器的 IP 地址或主机名。 |
| username | required | (none) | String | 连接到 MySQL 数据库服务器时要使用的 MySQL 用户名称。 |
| password | required | (none) | String | 连接到 MySQL 数据库服务器时使用的密码。 |
| database-name | required | (none) | String | 要监控的 MySQL 服务器的数据库名称。 database-name 还支持正则表达式来监控多个表是否匹配正则表达式。 |
| table-name | required | (none) | String | 要监控的 MySQL 数据库的表名。 table-name 还支持正则表达式来监控多个表是否匹配正则表达式。 |
| port | optional | 3306 | Integer | MySQL 数据库服务器的整数端口号。 |
| server-id | optional | (none) | Integer | 此数据库客户端的数字 Id 或数字 Id 范围,数字 Id 语法类似于 '5400', 数字 Id 范围语法类似于“5400-5408”,启用“scan.incremental.snapshot.enabled”时建议使用数字 Id 范围语法。 在 MySQL 集群中所有当前运行的数据库进程中,每个 Id 都必须是唯一的。此连接器加入 MySQL 集群 作为另一台服务器(具有此唯一 Id),因此它可以读取 Binlog。默认情况下,会生成一个介于 5400 和 6400 之间的随机数, 尽管我们建议设置一个明确的值。 |
| scan.incremental.snapshot.enabled | optional | true | Boolean | 增量快照是一种读取表快照的新机制。与旧的快照机制相比, 增量快照有很多优点,包括: (1) 快照读取时 Source 可以并行, (2) Source 可以在快照读取时在 Chunk 粒度上进行检查点, (3) Source 在读快照前不需要获取全局读锁(FLUSH TABLES WITH READ LOCK)。 如果您希望源代码并行运行,每个并行阅读器都应该有一个唯一的服务器 ID,所以 'server-id' 必须是 '5400-6400' 这样的范围,并且范围必须大于并行度。 请参阅增量快照阅读部分了解更多详细信息。 |
| scan.incremental.snapshot.chunk.size | optional | 8096 | Integer | 表快照的块大小(行数),读取表的快照时,表的快照被分成多个块。 |
| scan.snapshot.fetch.size | optional | 1024 | Integer | 读取表快照时每次轮询的最大获取大小。 |
| scan.startup.mode | optional | initial | String | MySQL CDC 消费者的可选启动模式,有效枚举为"initial" 和"latest-offset"。 请参阅启动阅读位置部分了解更多详细信息。 |
| server-time-zone | optional | UTC | String | 数据库服务器中的会话时区,例如"Asia/Shanghai"。 它控制 MYSQL 中的 TIMESTAMP 类型如何转换为 STRING。 查看更多这里。 |
| debezium.min.row. count.to.stream.result | optional | 1000 | Integer | 在快照操作期间,连接器将查询每个包含的表,以便为该表中的所有行生成读取事件。此参数确定 MySQL 连接是否会将表的所有结果拉入内存(速度很快但需要大量内存),或者是否将结果改为流式传输(可能较慢,但适用于非常大的表)。该值指定在连接器流式传输结果之前表必须包含的最小行数,默认为 1,000。将此参数设置为'0'以跳过所有表大小检查并始终在快照期间流式传输所有结果。 |
| connect.timeout | optional | 30s | Duration | 连接器在尝试连接到 MySQL 数据库服务器后在超时之前应等待的最长时间。 |
| connect.max-retries | optional | 3 | Integer | 连接器应重试以建立 MySQL 数据库服务器连接的最大重试次数。 |
| connection.pool.size | optional | 20 | Integer | 连接池大小。 |
| jdbc.properties.* | optional | 20 | String | 传递自定义 JDBC URL 属性的选项。用户可以传递自定义属性,例如 'jdbc.properties.useSSL' = 'false'。 |
| heartbeat.interval | optional | 30s | Duration | 发送心跳事件的时间间隔,用于跟踪最新可用的 Binlog 偏移量。 |
| append-mode | optional | false | Boolean | 是否仅支持 Append,如果为 'true',MySQL Extract Node 会将所有 Upsert 流转换为 Append 流,以支持不支持 Upsert 流的下游场景。 |
| migrate-all | optional | false | Boolean | 是否是全库迁移场景,如果为 'true',MySQL Extract Node 则将表的物理字段和其他元字段压缩成 'json' 格式的特殊 'data' 元字段, 目前支持两种 data 格式, 如果需要 'canal json' 格式的数据, 则使用 'data_canal' 元数据字段,如果需要使用 'debezium json' 格式的数据则使用 'data_debezium' 元数据字段。 |
| row-kinds-filtered | optional | false | Boolean | 需要保留的特定的操作类型,其中 +U 对应更新前的数据,-U 对应更新后的数据,+I 对应 插入的数据(存量数据为插入类型的数据),-D 代表删除的数据, 如需保留多个操作类型则使用 & 连接。 举例 +I&-D,connector 只会输出插入以及删除的数据,更新的数据则不会输出。 |
| debezium.* | optional | (none) | String | 将 Debezium 的属性传递给用于从 MySQL 服务器捕获数据更改的 Debezium Embedded Engine。 例如:'debezium.snapshot.mode' = 'never'。 详细了解 Debezium 的 MySQL 连接器属性。 |
| inlong.metric.labels | 可选 | (none) | String | inlong metric 的标签值,该值的构成为groupId=[groupId]&streamId=[streamId]&nodeId=[nodeId]。 |
可用的元数据字段
以下格式元数据可以作为表定义中的只读 (VIRTUAL) 列公开。
| 字段名称 | 数据类型 | 描述 |
|---|---|---|
| meta.table_name | STRING NOT NULL | 该行所属的表名。 |
| meta.database_name | STRING NOT NULL | 该行所属的数据库名称。 |
| meta.op_ts | TIMESTAMP_LTZ(3) NOT NULL | 它指示在数据库中进行更改的时间。 如果记录是从表的快照而不是binlog中读取的,则该值始终为0。 |
| meta.op_type | STRING | 数据库操作的类型,如 INSERT/DELETE 等。 |
| meta.data_canal | STRING/BYTES | `canal-json` 格式化的行的数据只有在 `migrate-all` 选项为 'true' 时才存在。 |
| meta.data_debezium | STRING/BYTES | `debezium-json` 格式化的行的数据只有在 `migrate-all` 选项为 'true' 时才存在。 |
| meta.is_ddl | BOOLEAN | 是否是 DDL 语句。 |
| meta.ts | TIMESTAMP_LTZ(3) NOT NULL | 接收和处理行的当前时间。 |
| meta.sql_type | MAP | 将 Sql_type 表字段映射到 Java 数据类型 Id。 |
| meta.mysql_type | MAP | 表的结构。 |
| meta.pk_names | ARRAY | 表的主键名称。 |
| meta.batch_id | BIGINT | Binlog的批次id。 |
| meta.update_before | ARRAY | 该行更新前的数据。 |
扩展的 CREATE TABLE 示例演示了使用这些元数据字段的语法:
CREATE TABLE `mysql_extract_node` (
`id` INT,
`name` STRING,
`database_name` string METADATA FROM 'meta.database_name',
`table_name` string METADATA FROM 'meta.table_name',
`op_ts` timestamp(3) METADATA FROM 'meta.op_ts',
`op_type` string METADATA FROM 'meta.op_type',
`batch_id` bigint METADATA FROM 'meta.batch_id',
`is_ddl` boolean METADATA FROM 'meta.is_ddl',
`update_before` ARRAY<MAP<STRING, STRING>> METADATA FROM 'meta.update_before',
`mysql_type` MAP<STRING, STRING> METADATA FROM 'meta.mysql_type',
`pk_names` ARRAY<STRING> METADATA FROM 'meta.pk_names',
`data` STRING METADATA FROM 'meta.data_canal',
`sql_type` MAP<STRING, INT> METADATA FROM 'meta.sql_type',
`ingestion_ts` TIMESTAMP(3) METADATA FROM 'meta.ts',
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc-inlong',
'hostname' = 'YourHostname',
'migrate-all' = 'true',
'port' = '3306',
'username' = 'YourUsername',
'password' = 'YourPassword',
'database-name' = 'YourDatabase',
'table-name' = 'YourTable',
'row-kinds-filtered' = '+I'
);
数据类型映射
| MySQL type | Flink SQL type | NOTE |
|---|---|---|
| TINYINT | TINYINT | |
| SMALLINT TINYINT UNSIGNED | SMALLINT | |
| INT MEDIUMINT SMALLINT UNSIGNED | INT | |
| BIGINT INT UNSIGNED | BIGINT | |
| BIGINT UNSIGNED | DECIMAL(20, 0) | |
| REAL FLOAT | FLOAT | |
| DOUBLE | DOUBLE | |
| NUMERIC(p, s) DECIMAL(p, s) where p <= 38 | DECIMAL(p, s) | |
| NUMERIC(p, s) DECIMAL(p, s) where 38 < p <= 65 | STRING | The precision for DECIMAL data type is up to 65 in MySQL, but the precision for DECIMAL is limited to 38 in Flink. So if you define a decimal column whose precision is greater than 38, you should map it to STRING to avoid precision loss. |
| BOOLEAN TINYINT(1) BIT(1) | BOOLEAN | |
| DATE | DATE | |
| TIME [(p)] | TIME [(p)] | |
| TIMESTAMP [(p)] DATETIME [(p)] | TIMESTAMP [(p)] | |
| CHAR(n) | CHAR(n) | |
| VARCHAR(n) | VARCHAR(n) | |
| BIT(n) | BINARY(⌈n/8⌉) | |
| BINARY(n) | BINARY(n) | |
| VARBINARY(N) | VARBINARY(N) | |
| TINYTEXT TEXT MEDIUMTEXT LONGTEXT | STRING | |
| TINYBLOB BLOB MEDIUMBLOB LONGBLOB | BYTES | Currently, for BLOB data type in MySQL, only the blob whose length isn't greater than 2,147,483,647(2 ** 31 - 1) is supported. |
| YEAR | INT | |
| ENUM | STRING | |
| JSON | STRING | The JSON data type will be converted into STRING with JSON format in Flink. |
| SET | ARRAY<STRING> | As the SET data type in MySQL is a string object that can have zero or more values, it should always be mapped to an array of string |
特性
多库多表同步
Mysql Extract 节点支持整库、多表同步。开启该功能后,Mysql Extract 节点会将表的物理字段压缩成 'canal-json' 格式的特殊元字段 'data_canal',也可配置为 'debezium-json' 格式的元数据字段 'data_debezium'。
配置参数:
| 参数 | 是否必须 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| migrate-all | optional | false | String | 开启整库迁移模式,所有的物理字段通过 data_canal 字段获取 |
| table-name | optional | false | String | 需要读取的表的正则表达式,database 和 table 之间使用 "." 分隔,多个正则表达式使用 "," 分隔 |
| database-name | optional | false | String | 需要读取的库的表达式,多个正则表达式使用 "," 分隔 |
CREATE TABLE 示例演示该功能语法:
CREATE TABLE `table_1`(
`data` STRING METADATA FROM 'meta.data_canal' VIRTUAL)
WITH (
'inlong.metric.labels' = 'groupId=1&streamId=1&nodeId=1',
'migrate-all' = 'true',
'connector' = 'mysql-cdc-inlong',
'hostname' = 'localhost',
'database-name' = 'test,test01',
'username' = 'root',
'password' = 'inlong',
'table-name' = 'test01\.a{2}[0-9]$, test\.[\s\S]*'
)