Hive
Overview
Hive Load Node can write data to hive. Using the flink dialect, the insert operation is currently supported, and the data in the upsert mode will be converted into insert. Manipulating hive tables using the hive dialect is currently not supported.
Supported Version
| Load Node | Version |
|---|---|
| Hive | Hive: 1.x, 2.x, 3.x |
Dependencies
Using Hive load requires the introduction of dependencies. Of course, you can also use INLONG to provide jar packages.(sort-connector-hive)
Maven dependency
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-hive</artifactId>
<version>1.9.0</version>
</dependency>
How to create a Hive Load Node
Usage for SQL API
The example below shows how to create a Hive Load Node with Flink SQL Cli :
CREATE TABLE hiveTableName (
id STRING,
name STRING,
uv BIGINT,
pv BIGINT
) WITH (
'connector' = 'hive',
'default-database' = 'default',
'hive-version' = '3.1.2',
'hive-conf-dir' = 'hdfs://localhost:9000/user/hive/hive-site.xml'
);
Usage for InLong Dashboard
Configuration
When creating a data stream, select Hive for the data stream direction, and click "Add" to configure it.
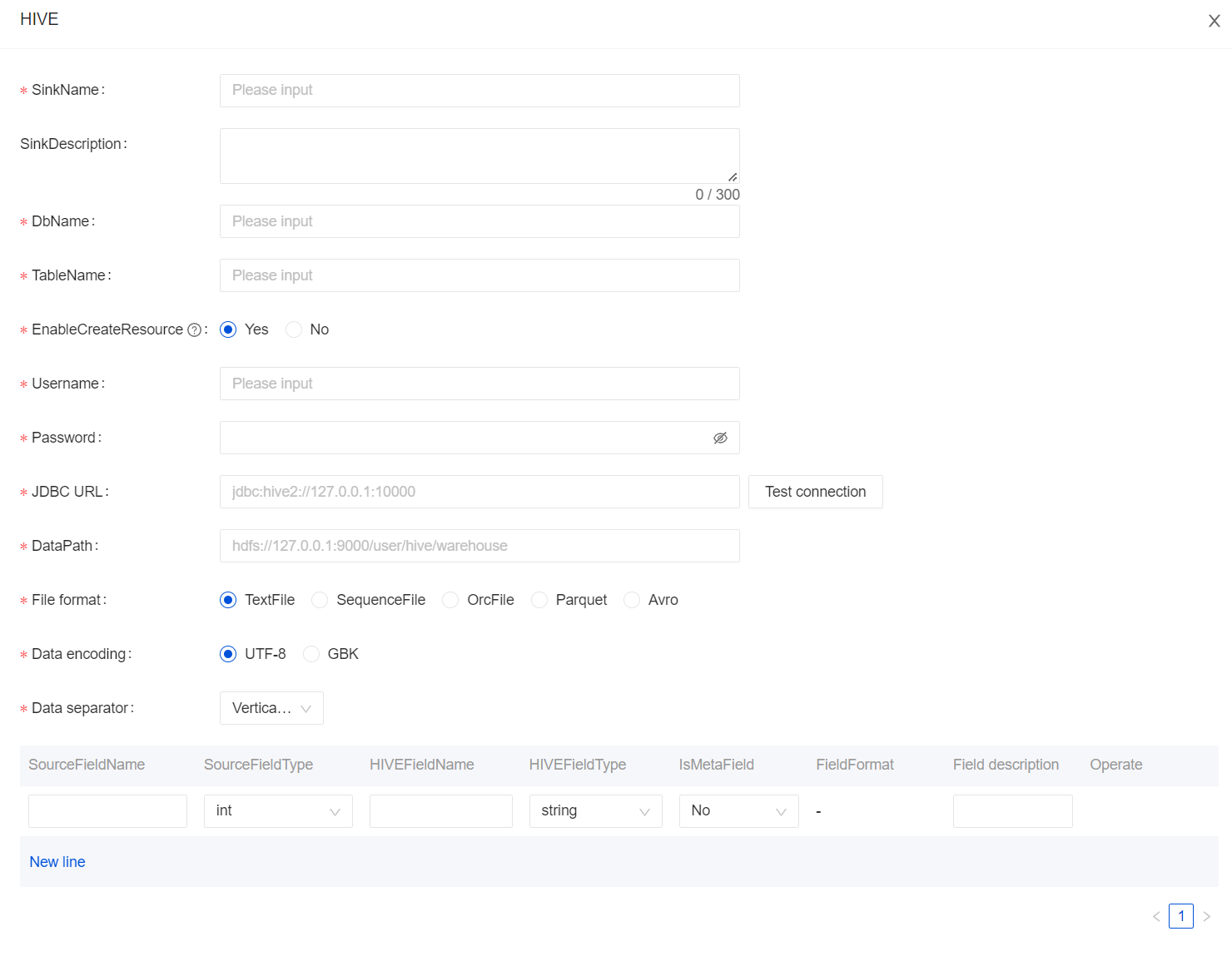
Usage for InLong Manager Client
TODO: It will be supported in the future.
Hive Load Node Options
| Option | Required | Default | Type | Description |
|---|---|---|---|---|
| connector | required | (none) | String | Specify what connector to use, here should be 'hive'. |
| default-database | required | (none) | String | |
| hive-conf-dir | required | (none) | String | If you don't want to upload hive-site.xml to HDFS, you can put this configuration into the classpath of the project, and then this place only needs to be not empty, otherwise you must fill in the complete HDFS URL. |
| sink.partition-commit.trigger | optional | (none) | String | If hive exists partition you can set trigger mode.(process-time) |
| partition.time-extractor.timestamp-pattern | optional | (none) | String | If hive exists partition you can set timestamp-pattern mode.(yyyy-MM-dd...) |
| sink.partition-commit.delay | optional | (none) | String | If hive exists partition you can set delay mode.(10s,20s,1m...) |
| sink.partition-commit.policy.kind | optional | (none) | String | Policy to commit a partition is to notify the downstream application that the partition has finished writing, the partition is ready to be read. metastore: add partition to metastore. Only hive table supports metastore policy, file system manages partitions through directory structure. success-file: add '_success' file to directory. Both can be configured at the same time: 'metastore,success-file'. custom: use policy class to create a commit policy. Support to configure multiple policies: 'metastore,success-file'. |
| inlong.metric.labels | optional | (none) | String | Inlong metric label, format of value is groupId=[groupId]&streamId=[streamId]&nodeId=[nodeId]. |
Data Type Mapping
| Hive type | Flink SQL type |
|---|---|
| char(p) | CHAR(p) |
| varchar(p) | VARCHAR(p) |
| string | STRING |
| boolean | BOOLEAN |
| tinyint | TINYINT |
| smallint | SMALLINT |
| int | INT |
| bigint | BIGINT |
| float | FLOAT |
| double | DOUBLE |
| decimal(p, s) | DECIMAL(p, s) |
| date | DATE |
| timestamp(9) | TIMESTAMP |
| bytes | BINARY |
| array | LIST |
| map | MAP |
| row | STRUCT |