Hive
概览
Hive 加载节点可以将数据写入 Hive。使用 Flink 方言,目前仅支持 Insert 操作,Upsert 模式下的数据会转换成 Insert 方式 目前暂时不支持使用 Hive 方言操作 Hive 表。
支持的版本
| Load Node | Version |
|---|---|
| Hive | Hive: 1.x, 2.x, 3.x |
依赖
通过 Maven 引入 sort-connector-hive 构建自己的项目。 当然,你也可以直接使用 INLONG 提供的 jar 包。(sort-connector-hive)
Maven 依赖
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-hive</artifactId>
<version>1.9.0</version>
</dependency>
如何配置 Hive 数据加载节点
SQL API 的使用
使用 Flink SQL Cli :
CREATE TABLE hiveTableName (
id STRING,
name STRING,
uv BIGINT,
pv BIGINT
) WITH (
'connector' = 'hive',
'default-database' = 'default',
'hive-version' = '3.1.2',
'hive-conf-dir' = 'hdfs://localhost:9000/user/hive/hive-site.xml'
);
InLong Dashboard 方式
配置
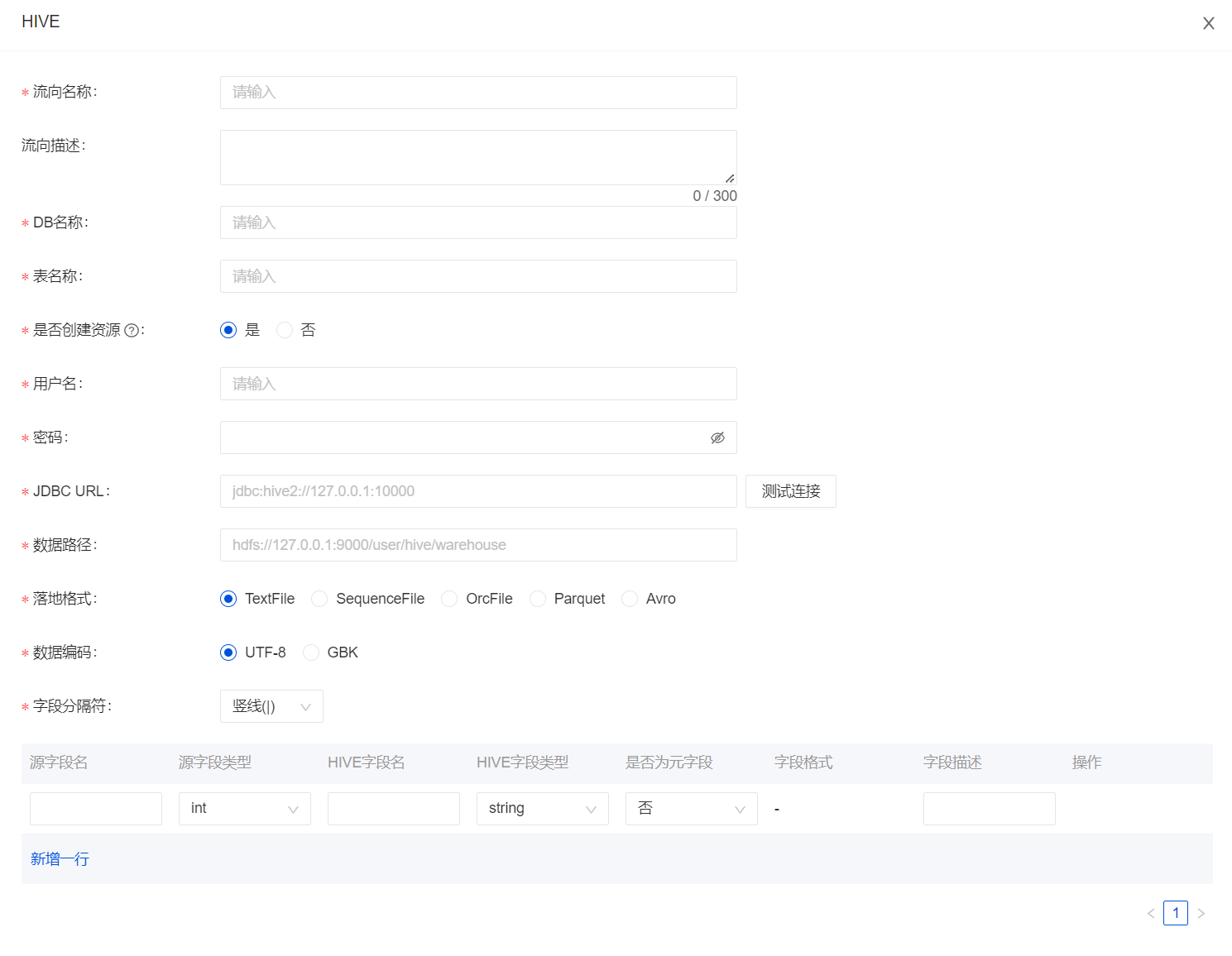
在创建数据流时,选择数据落地为 'Hive' 然后点击 'Add' 来配置 Hive 的相关信息。
InLong Manager Client 方式
TODO: 未来版本支持
Hive 加载节点参数信息
| 参数 | 是否必须 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | 必须 | (none) | String | 指定使用什么连接器,这里应该是 'hive'。 |
| default-database | 必须 | (none) | String | 指定数据库名称。 |
| hive-conf-dir | 必须 | (none) | String | 本地构建项目可以将 hive-site.xml 构建到 classpath 中,未来 Dashboard 将支持本地上传能力。 目前通用方式只支持配置已经上传文件后的 HDFS 路径。 |
| sink.partition-commit.trigger | 可选 | (none) | String | 如果表是分区表,可以配置触发模式。如:(process-time) |
| partition.time-extractor.timestamp-pattern | 可选 | (none) | String | 如果表是分区表,可以配置时间戳。如:(yyyy-MM-dd) |
| sink.partition-commit.delay | 可选 | (none) | String | 如果表是分区表,可以配置延迟时间。如:(10s,20s,1m...) |
| sink.partition-commit.policy.kind | 可选 | (none) | String | 分区提交策略通知下游某个分区已经写完毕可以被读取了。 metastore:向 metadata 增加分区。仅 hive 支持 metastore 策略,文件系统通过目录结构管理分区; success-file:在目录中增加 '_success' 文件; 上述两个策略可以同时指定:'metastore,success-file'。 custom:通过指定的类来创建提交策略, 支持同时指定多个提交策略:'metastore,success-file'。 |
| inlong.metric.labels | 可选 | (none) | String | inlong metric 的标签值,该值的构成为 groupId=[groupId]&streamId=[streamId]&nodeId=[nodeId]。 |
数据类型映射
| Hive type | Flink SQL type |
|---|---|
| char(p) | CHAR(p) |
| varchar(p) | VARCHAR(p) |
| string | STRING |
| boolean | BOOLEAN |
| tinyint | TINYINT |
| smallint | SMALLINT |
| int | INT |
| bigint | BIGINT |
| float | FLOAT |
| double | DOUBLE |
| decimal(p, s) | DECIMAL(p, s) |
| date | DATE |
| timestamp(9) | TIMESTAMP |
| bytes | BINARY |
| array | LIST |
| map | MAP |
| row | STRUCT |